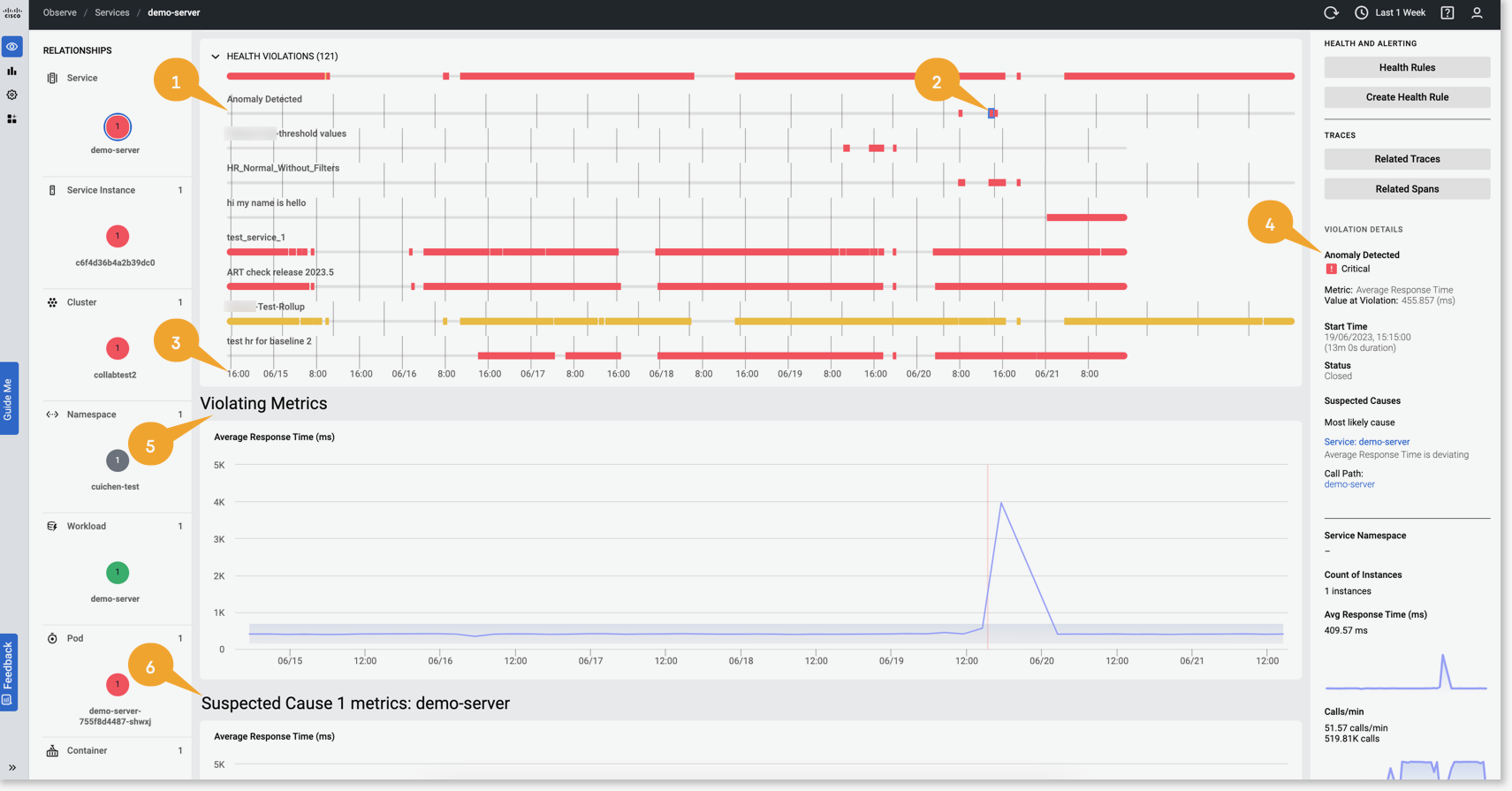
Cisco Cloud Observability エンティティの正常性の監視 異常検知 Current: 異常のモニタリング PDF Download PDF Download page 異常のモニタリング. Current page All pages 異常のモニタリング 異常検知は、アプリケーションのエンティティタイプに対してデフォルトで有効になっています。機械学習がアプリケーションのエンティティタイプでモデルトレーニングを行うには 48 時間かかります。「モデルトレーニング」を参照してください。エンティティタイプのモデルをトレーニングすると、アプリケーションに関連付けられた異常を監視し、違反しているメトリックの詳細を特定できます。異常を監視するには、次の手順を実行します。Observe をクリックします。次のいずれかのドメインに移動します。アプリケーション パフォーマンス モニタリングインフラストラクチャエンティティタイプを選択します。ドメインエンティティタイプアプリケーション パフォーマンス モニタリングビジネス トランザクション、サービス、サービス エンドポイント、またはサービス インスタンスインフラストラクチャ[ホスト(Hosts)] 異常検知は、AWS EC2、AWS Application Load Balancer、および AWS Classic Load Balancer でのみサポートされています。 たとえば、アプリケーション パフォーマンス モニタリングからエンティティタイプ [Service.] を選択します。 サービスの詳細ページには、関係マップ、正常性違反(異常を含む)、および違反しているメトリックが一覧表示されます。エンティティ名をクリックして異常を調べます。 アプリケーション パフォーマンス モニタリング ドメインの場合、[List] をクリックしてエンティティ名のリストを表示します。 異常の検査[HEALTH VIOLATIONS] タイムラインと右側のパネルの [HEALTH AND ALERTING] セクションで、違反している異常に関連するデータを表示できます。このデータは、違反している正確なメトリックを特定し、修正処置を取るのに役立つ関連する詳細を提供します。[HEALTH VIOLATIONS] セクションの [Anomaly Detection] タイムライン には、選択したサービスに関連付けられた違反している異常のリストが、[Critical] または [Warning] のステータスとともに表示されます。赤は [Critical] ステータス を示し、黄色は [Warning] ステータスを示します。異常違反のタイムラインと正常性違反の開始時刻 が下部に表示されます。異常がオープン状態の場合、異常違反の終了時刻は現在時刻です。異常がクローズ状態の場合、開始時刻と終了時刻は異常違反の履歴の時刻を示します。セクションの違反の詳細は、特定のサービスの異常の全体的なステータスを示します。HEALTH AND ALERTING 異常ごとに、違反メトリックと疑わしい原因メトリックのタイムライングラフが表示されます。次の図は、番号が付けられた異常の詳細を示しています。データが使用できない場合、またはソースからフローしている場合は、異常を評価できません。データがない期間は、異常ステータスは不明になります。[HEALTH VIOLATIONS] セクション、[Violating Metrics] グラフ、および [Suspected Cause metrics] グラフの異常検知タイムラインでは、データなしの期間が灰色で表示されます。異常の詳細の表示右側のパネルには、次の違反の詳細が表示されます。サービス名違反メトリック名違反メトリックの平均値違反の開始日時と期間違反のステータス (オープンまたはクローズ)疑わしい原因(上位 3 つの疑わしい原因をリストします) 疑わしい原因ごとに、サービス名、ID、影響を受けるエンティティのパス、逸脱しているメトリック、および関連するコールパスがリストされます。 コールパスX 軸にタイムラインがプロットされた違反メトリックと疑わしい原因メトリックのグラフサービス名やサービス名前空間などのその他のプロパティ異常データ分析エンティティ中心のページと [Properties] ペインには、異常に関連付けられたデータを表示し、根本原因と影響を受ける依存サービスをすばやく特定するための次のオプションが用意されています。異常にカーソルを合わせると、異常の重大度レベル、開始時刻、他の重大度レベルへの遷移(たとえば、重大から警告)、および異常が解決された場合の終了時刻が表示されます。異常タイムラインで異常を選択します。右側のパネルに、上位 3 つの疑わしい原因のリストが、根本原因である可能性が最も高い疑わしい原因が最初となる順序で表示されます。[Suspected Causes] セクションには、逸脱しているメトリックとともにコールパスが一覧表示されます。コールパスリンクを表示して、(サービスコンテキストで)異常の伝播を追跡します。コールパスには、異常の影響を受ける可能性のあるすべてのエンティティが一覧表示されます。 コールパス上のエンティティをクリックします。エンティティの依存関係フローマップ、サービスのエンドポイント、関連するメトリック値などのその他の詳細も表示されます。これらの詳細は、異常の原因を特定し、影響を受けるパスを推定するのに役立ちます。[Violating Metrics] または [Suspected Cause metric] グラフを調べて、逸脱しているメトリックデータを違反メトリックデータと関連付けます。違反または疑わしい原因メトリックを表示、スクロール、およびカーソルを合わせて、偏差を判別します。メトリック値は、細い青い線で表示されます。時間ポイントにカーソルを合わせると、メトリック値を数値形式で表示できます。グラフでは、メトリックの上限と下限 (しきい値) を表示できます。Violating Metrics この上限と下限が、メトリックの通常の範囲を定義します。正常範囲のコンテキストでメトリックを観察することにより、異常なメトリック値を特定できます。異常データ分析により、根本原因を特定するために各依存関係に関する複数のメトリックを調査するという面倒なプロセスが不要になります。その代わりに、タイムライン、フローマップ、およびメトリックの概要をさっと見て、リストされている疑わしい原因を確認または否定するだけです。異常の根本原因の特定 では根本原因分析について例とともに説明します。 ×