Cisco Cloud Observability は、次のエンティティタイプで見つかった異常の疑わしい原因を識別して表示します。
| ドメイン | エンティティタイプ |
|---|
| アプリケーション パフォーマンス モニタリング | ビジネストランザクション |
| サービス |
| サービスインスタンス |
| サービスエンドポイント |
異常の根本原因を理解するために、サービスのパフォーマンスの問題の例を考えてみましょう(OrderServiceVodka)。この例では、異常が表面化してから根本原因が確認されるまでを追跡し、このページの [Health Violation ] セクションから始めることを想定しています。
このページでは、利用可能なデータを分析して異常の根本原因を特定するためのいくつかのオプションについて説明します。
異常の詳細の表示
異常を分析し、サービスの応答が遅い理由を特定するには、異常の詳細を調べることから始めます。
最新のデータが表示されるように、適切な時間範囲を選択します。
- Health Violation タイムラインを展開して Anomaly Detected タイムラインを表示します。
- タイムラインで異常イベントを選択します。異常の詳細が右側のパネルに表示されます。
- この単純な異常は [Critical] 状態で始まり、そのライフサイクルのほとんどで継続するため、最初のイベントに集中できます。場合によっては、何度か状態変化することがあります。このような場合、複数のアラートイベントを調べると役に立つ場合があります。
依存関係フローマップの調査
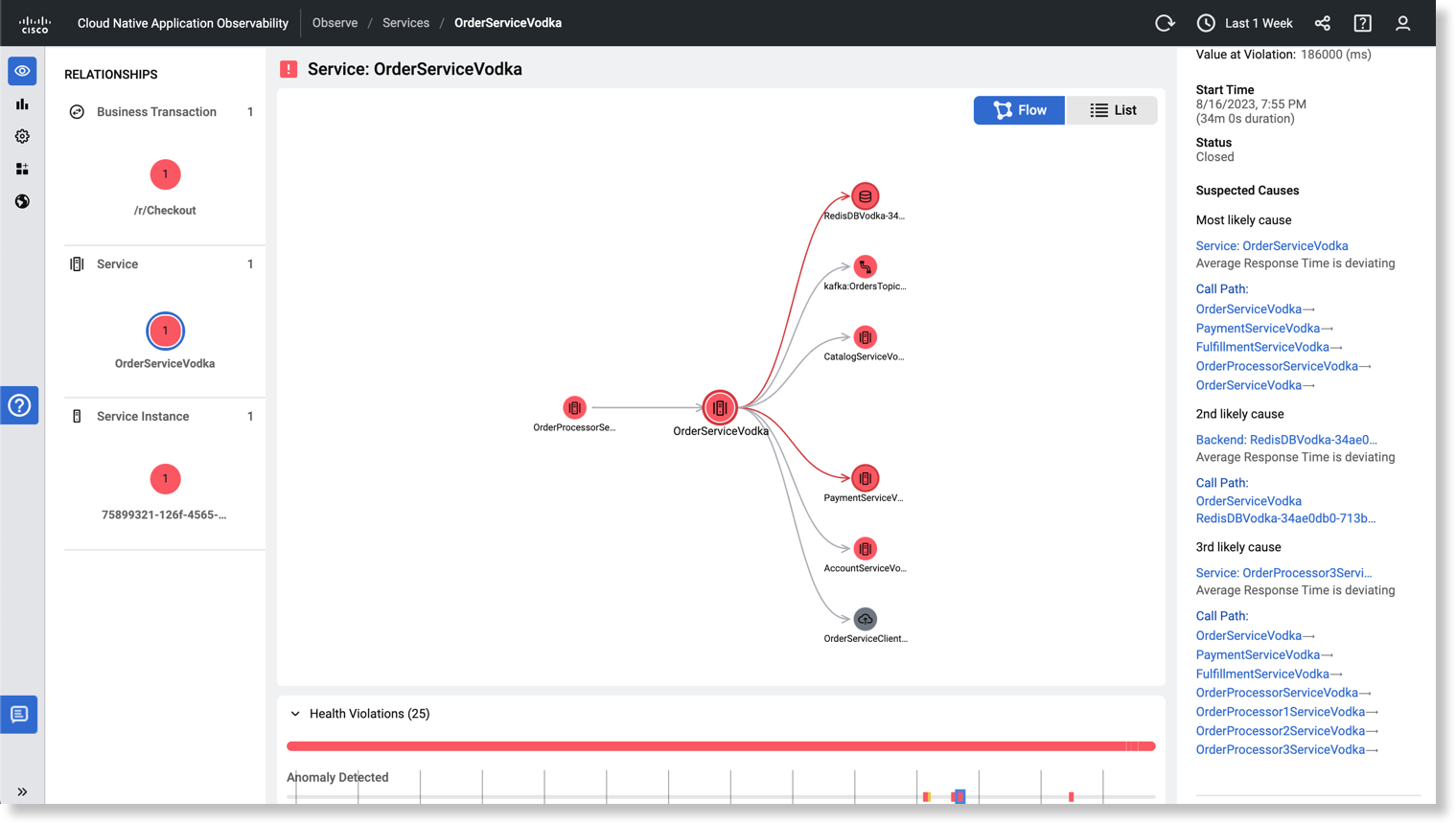
依存関係フローマップには、影響を受けるサービス OrderServiceVodka と、異常の影響を受ける可能性のあるその依存関係が一覧表示されます。この例では、サービス OrderServiceVodka の平均応答時間が違反しています。[Health Violations] セクションで [Anomaly Detected] イベントをクリックすると、疑わしいすべてのコールパスが強調表示されます。コールパスでは、異常なサービスを表示できます。フローマップの例では、異常なサービスは赤色で示されています。
疑わしい原因の調査
異常の [Suspected Causes ] では、上位 3 つの根本原因([Most likely cause]、[2nd likely cause]、および [3rd likely cause])を表示できます。最も可能性の高い根本原因は [Most likely cause] として、次に可能性の高い根本原因は [2nd likely cause] として、3 番目に可能性の高い根本原因は [3rd likely cause] として表示されます。ただし、一部の異常では、[Most likely cause] のみが表示される場合があります。この例では、Service: OrderServiceVodka が 1 番目の疑わしい原因であるため、最も可能性の高い根本原因です。1 番目の疑わしい原因を調べることから始めます。
現在 Cisco Cloud Observability は、サービスエンドポイントで検知された異常の疑わしい原因を特定しません。
[Most likely Cause] の調査
この疑わしい原因は、問題が Service: OrderServiceVodkaAverage Response Time (ART) に注意してください。 [Flow] マップ上で、[Most likely cause] セクションの下の [Call Path] をクリックすると、強調表示されたコールパスを表示できます。
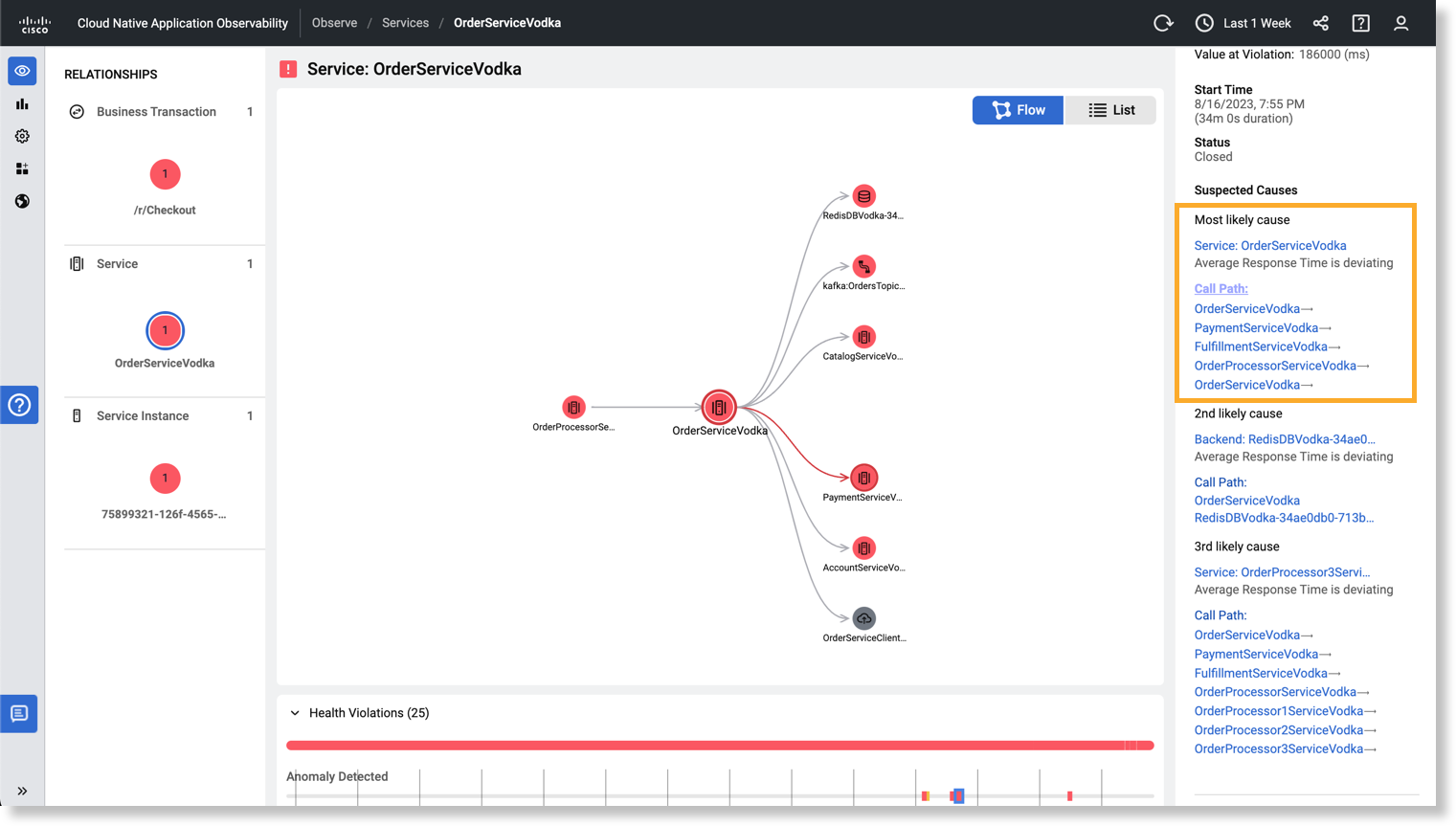
コールパスは、異常の伝達を追跡するのに役立ちます。次の点に注意してください。
PaymentServiceVodka が異常であるため、OrderServiceVodka が異常です。 FulfillmentServiceVodka が異常であるため、PaymentServiceVodka が異常です。OrderProcessorServiceVodka が異常であるため、FulfillmentServiceVodka が異常です(以下同様)。
各サービスをクリックすると、そのコールパスが表示されます。各サービスのエンドポイントの詳細を表示することもできます。ここでは、さまざまなエンドポイントのパフォーマンス値を表形式で比較します。これらの詳細により、逸脱しているメトリックと、対応するエンドポイントをすばやく絞り込むことができます。
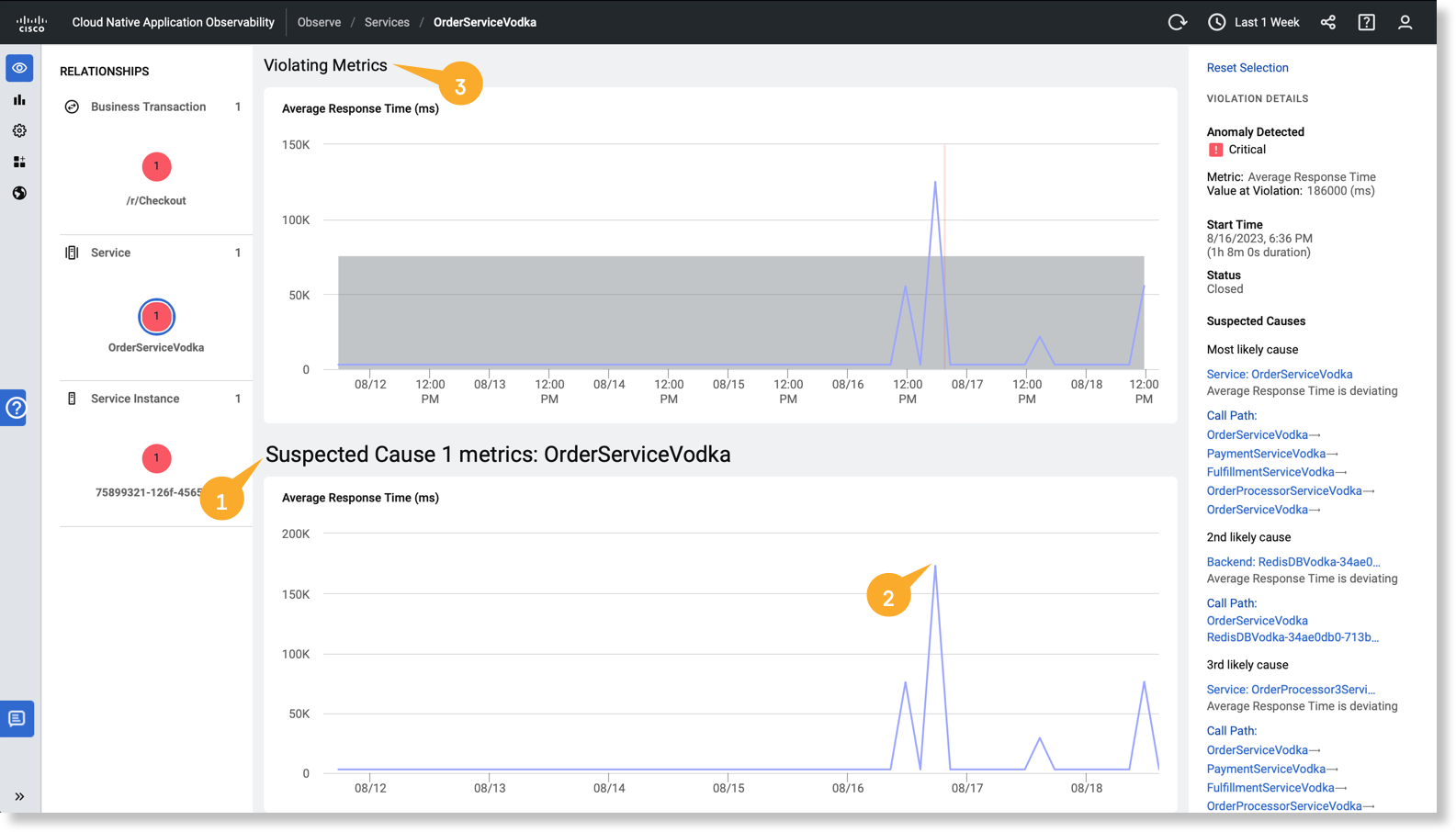
[Suspected Cause 1 metrics: OrderServiceVodka] グラフ では、異常が始まると、メトリック値が上昇します
では、異常が始まると、メトリック値が上昇します 。メトリック値を数値形式で表示するには、時間ポイントにカーソルを合わせます。
。メトリック値を数値形式で表示するには、時間ポイントにカーソルを合わせます。OrderServiceVodka の逸脱しているメトリックを表示し、違反しているメトリックと関連付けることができます 。違反しているメトリックの平均応答時間(ART)は、
。違反しているメトリックの平均応答時間(ART)は、OrderServiceVodka の ART と同様のパターンで同時に増加していることが確認できます。 グラフは、逸脱とパターンを関連付けるのに役立ちます。[Most likely cause] セクションでは、コールパスのサービスをクリックすると、正常性違反やメトリック パフォーマンス グラフなどのエンティティ固有の詳細を表示できます。
[2nd Likely Cause] の調査
この疑わしい原因は、問題がサービス Backend: RedisDBVodka-34ae0db0-713b-402a-80ff-9d065e891efd にある可能性があることを示しています。コールパスは、 RedisDBVodka-34ae0db0-713b-402a-80ff-9d065e891efd が OrderServiceVodka に影響することを示しています。[Flow] マップ上で、[2nd likely cause] セクションの下の [Call Path] をクリックすると、強調表示されたコールパスを表示できます。
[3rd Likely Cause] の調査
この疑わしい原因は、問題がサービス OrderProcessor3ServiceVodka にある可能性があることを示しています。コールパスは、OrderProcessor3ServiceVodka が間にある複数のサービスとともに OrderServiceVodka に影響することを示しています。
まとめ
OrderServiceVodka サービスには、他のサービスやバックエンドを含む複数の依存関係があります。異常の詳細と疑わしい原因の情報を使用して、以下を迅速に排除します。
- サービスに関連するパフォーマンスの問題の一部を除くすべての原因、および
- サービスに関連する最も関連性の高い(逸脱している)メトリックを除くすべてのメトリック。
このプロセスにより、それぞれの依存関係について、複数のメトリックを調査するという面倒なプロセスが軽減されました。代わりに、タイムライン、フローマップ、およびメトリック パフォーマンス グラフを一目で確認して、疑わしい原因を確認または無効にします。異常検知と疑わしい原因の情報は、根本原因の特定に役立ち、仮説をすばやく形成して検証するために必要な情報を提供します。