Download PDF
Download page 異常検知.
異常検知
異常検知は、アプリケーションおよびインフラストラクチャでモニター対象のエンティティタイプのパフォーマンスが許容可能なパフォーマンス制限内にあるかどうかを自動的に判断します。次のエンティティ タイプが監視されます。
| ドメイン | エンティティタイプ |
|---|---|
| アプリケーション パフォーマンス モニタリング(APM) |
|
| インフラストラクチャ |
|
| Kubernetes を利用) |
|
この機能により、アプリケーション パフォーマンスの問題の平均検出時間(MTTD)を短縮できます。デフォルトでは、異常検知はすべてのエンティティタイプに対して有効になっています。クラウドテナントで利用可能な異常検知構成のデフォルトセットを使用できます。また、選択したエンティティタイプの異常検知を構成することもできます。「異常検知の構成」を参照してください。
異常検知の仕組み
異常検知は、機械学習機能を使用して、エンティティの待機時間、エラー、スループットを継続的に監視し、異常な動作を識別します。メトリックレベルでの手動構成を必要としないアルゴリズムを使用します。異常検知は、エンティティタイプの次のメトリックをモニターします。
| ドメイン | エンティティタイプ | メトリック |
|---|---|---|
| APM |
|
|
| インフラストラクチャ | AWS EC2 |
|
AWS Application Load Balancer |
| |
| AWS Classic Load Balancer |
| |
| Kubernetes を利用) | Cluster |
|
名前空間 |
| |
ワークロード |
| |
ポッド |
|
たとえば、異常検出アルゴリズムは、APM エンティティ タイプの次のメトリックを監視します。
[
Errors per Minute](EPM)メトリックに異常な測定値が報告されているかどうかを検出します。[Average Response Time](ART)メトリックに異常な測定値が報告されているかどうかを検出します。
次に、アラートノイズを減らすように設計されたヒューリスティックを使用して、これらのメトリックの測定値から学習したデータを結合します。
異常検知では、収集するメトリックデータの正確性を確保するために、複数の手法が使用されます。
- 一時的なスパイクやデータがない期間は無視されます。
- メトリックデータが正規化されます。たとえば、EPM メトリックデータを判断する場合、[
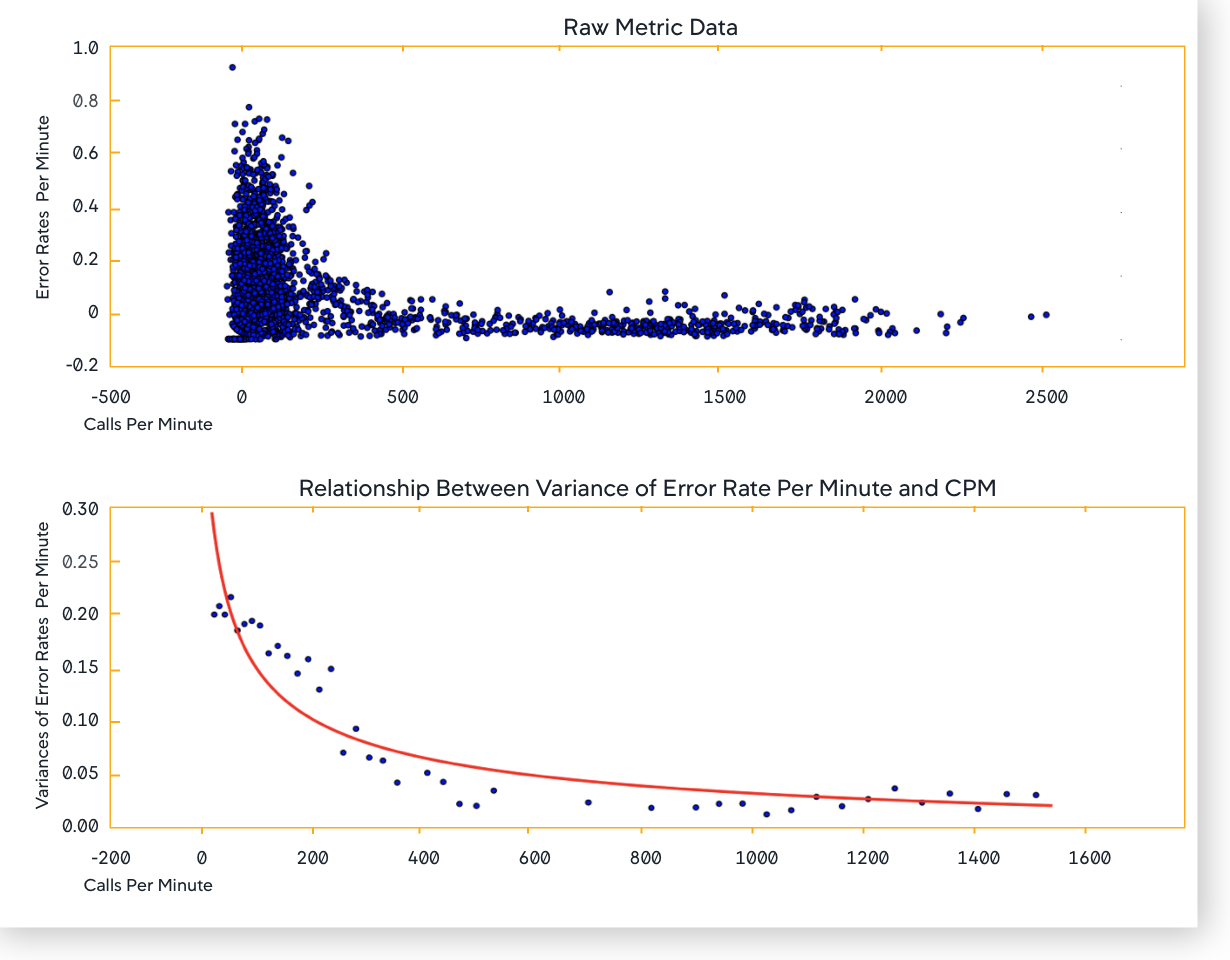
Calls per Minute](CPM)の対応する増加がない限り、スパイクが実際の問題を示しているとは限りません。EPM データ自体が有用でない可能性があるため、異常検知ではエラー率(EPM/CPM)が使用されます。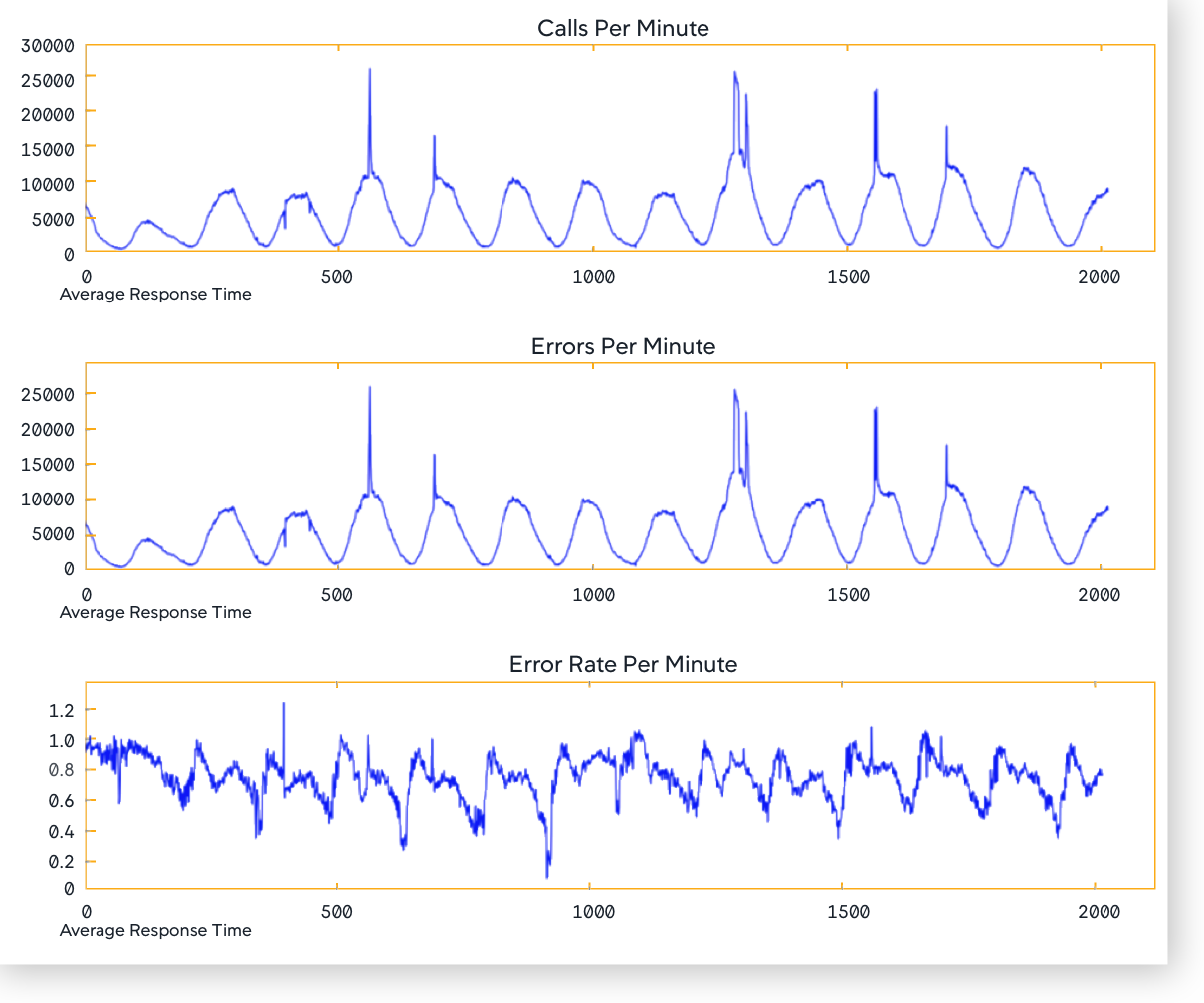
- 季節ベースラインを適用します。
異常検出アルゴリズムは、指標レベルのシグナルで日次および週次の季節性を検出します。ビジネスの季節性を考慮に入れています。その結果、正確なアラートが得られます。APM エンティティタイプの場合は、信頼性の高い結果を得るために、EPM と ART のバリアンスを CPM に関連付けます。
疑わしい原因と根本原因分析(RCA)
アプリケーションのエンティティに異常が発生するのには多くの理由があります。異常検知は AI 機能を使用して、RCA がすべての異常について疑わしい原因の特定を実行できるようにします。疑わしい原因、対応する逸脱メトリック、および疑わしい原因から影響を受けるエンティティへのコールパスを確認できます。疑わしい原因は、可能性の順にランク付けされます。したがって、最も可能性が高いと思われる原因から分析を開始できます。これにより、問題解決までの平均時間(MTTR)が短縮されます。疑わしい原因と根本原因の分析は、次のエンティティ タイプで利用できます。
| ドメイン | エンティティタイプ |
|---|---|
| APM | ビジネストランザクション |
サービス | |
サービスインスタンス | |
| サービスエンドポイント |
異常検知と正常性ルールの違い
異常検知と正常性ルールの両方がアプリケーションのパフォーマンス上の問題を警告しますが、異常検知は正常性ルールを使用して取得することが困難な強力なインサイトを提供します。
| 異常検知 | 正常性ルール |
|---|---|
異常検知は機械学習を使用して主要なアプリケーション エンティティ パフォーマンス メトリックの通常の範囲を検出し、これらのメトリックが予想される値から大幅に逸脱した場合に警告します。そのため、正常性ルールによって人手でキャプチャできるものよりも、幅広い範囲の問題を特定できます。 | 正常性ルールは手動で作成され、1 つ以上のメトリックを満たさなければならないという論理条件が適用されます。たとえば、ART をモニターして、このメトリックが構成されたベースラインから外れているかどうかを確認できます。 |
| 異常検知アルゴリズムは、メトリックレベルでの構成を必要としません。事前トレーニング済みのモデルを使用します。 | 正常性ルールを使用すると、エンティティの異常な動作を評価するために必要なパラメータと条件を完全に定義できます。 |
現在、異常は以下に関連付けられています。
| 正常性ルールは、クラスタ、サービス、ポッドなどのエンティティに適用されます。 |
モデルトレーニング
デフォルトでは、異常検知はすべての APM エンティティタイプに対して有効になっています。異常検知が監視対象エンティティに対して使用可能になるまでに 48 時間かかります。その間、アプリケーションのエンティティで機械学習モデルがトレーニングされます。
この表で、エンティティのトレーニングステータスについて説明します。POST/query/execute API オペレーションを使用して、これらのステータスを取得できます。詳細については、「Cisco AppDynamics Query Service API」を参照してください。
ステータス | 意味 |
|---|---|
| In Progress | Cisco Cloud Observability の機械学習がエンティティのデータの受信を開始し、モデルの作成が進行中です。 |
| Ready | モデルトレーニングが完了し、Cisco Cloud Observability で異常を検出する準備が整いました。 |
| Unknown | 現在のモデルの状態は不明です。これは、Cisco Cloud Observability 機械学習がエンティティのデータの受信を開始したばかりであるが、モデルが存在しない場合、または特定のエンティティのデータを受信しない場合に発生します。 |
| Not Available | Cisco Cloud Observability機械学習がデータを受け取りません。 |
モデルは継続的に更新されます。サービスへのトラフィックがその日のトレーニングの妨げになるのに十分な時間中断された場合、異常検知は過去 7 日間のモデルを使用します。
異常データの表示
モデルトレーニングが完了すると、検出された異常を表示して監視し、修正処置を講じることができます。「異常のモニタリング」を参照してください。