Download PDF
Download page 正常性違反のタイムライン.
正常性違反のタイムライン
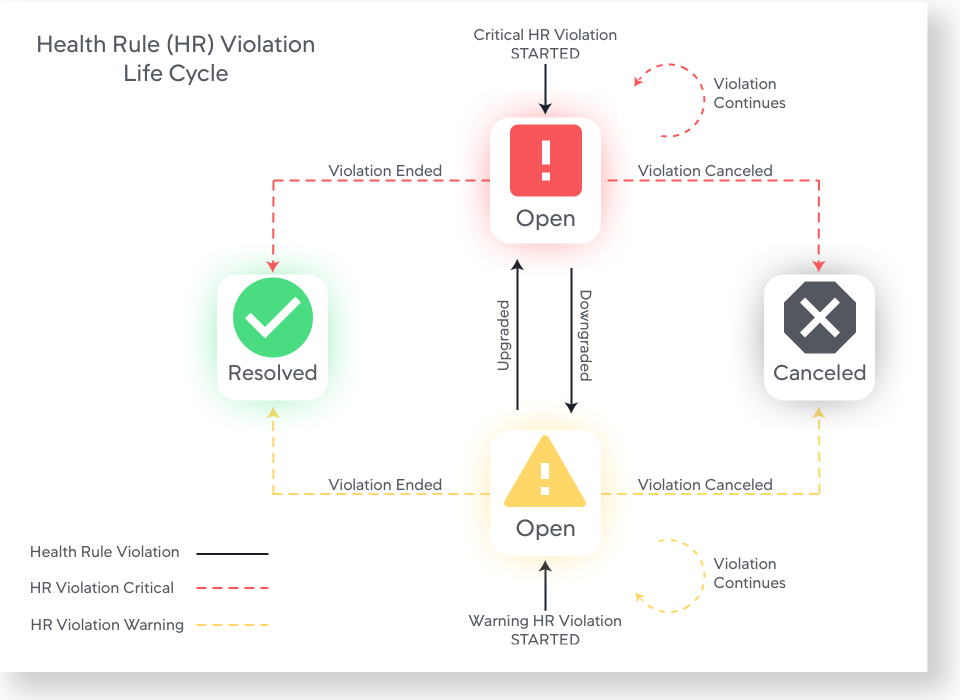
正常性ルール違反は、その正常性ルールに設定された重大または警告条件が true に評価された場合に発生します。この場合、[Violation Started - Critical] イベントまたは [Violation Started - Warning] イベントによって、Open ステータスの正常性ルール違反が生成されます。
次のどちらかのステータスになると、正常性ルール違反が終了します。
- 解決済み:違反した条件に当てはまらなくなったことを示すメトリックが報告されました。
違反ステータスが解決すると、[Violation Created - Critical ] イベント、[Violation Ended - Warning to Normal ] または [Violation Ended - Critical to Normal] イベントが生成されます。
または
- [Canceled]:正常性ルールの正常性違反ステータスが、違反が続いているか終了したかを正確に判断できない場合。この場合、正常性ルール違反のステータスが Canceled になります。 これは、以下の場合に発生する可能性があります。
- 正常性ルールが 編集された。
- 正常性ルールが無効になった。
- 正常性ルール評価エンティティが追加または削除された。
- 正常性ルール違反のメトリックの値が
UNKNOWN.になった
[Violation Ended] または [Violation Canceled] イベントは、正常性ルールの違反ステータスが [Canceled] に変更されたときに生成されます。
正常性ルール違反が解決済みまたはキャンセル済みになった後に、同じ正常性ルールに違反があった場合、新しい正常性ルール違反が開始されます。
1 つの正常性ルール違反の間に、Health Rule Violation Ungraded/Downgraded/Continues イベントのような他のタイプの正常性ルール違反イベントが存在する可能性も あります。
下図に、正常性ルール違反のライフ サイクルを示します。
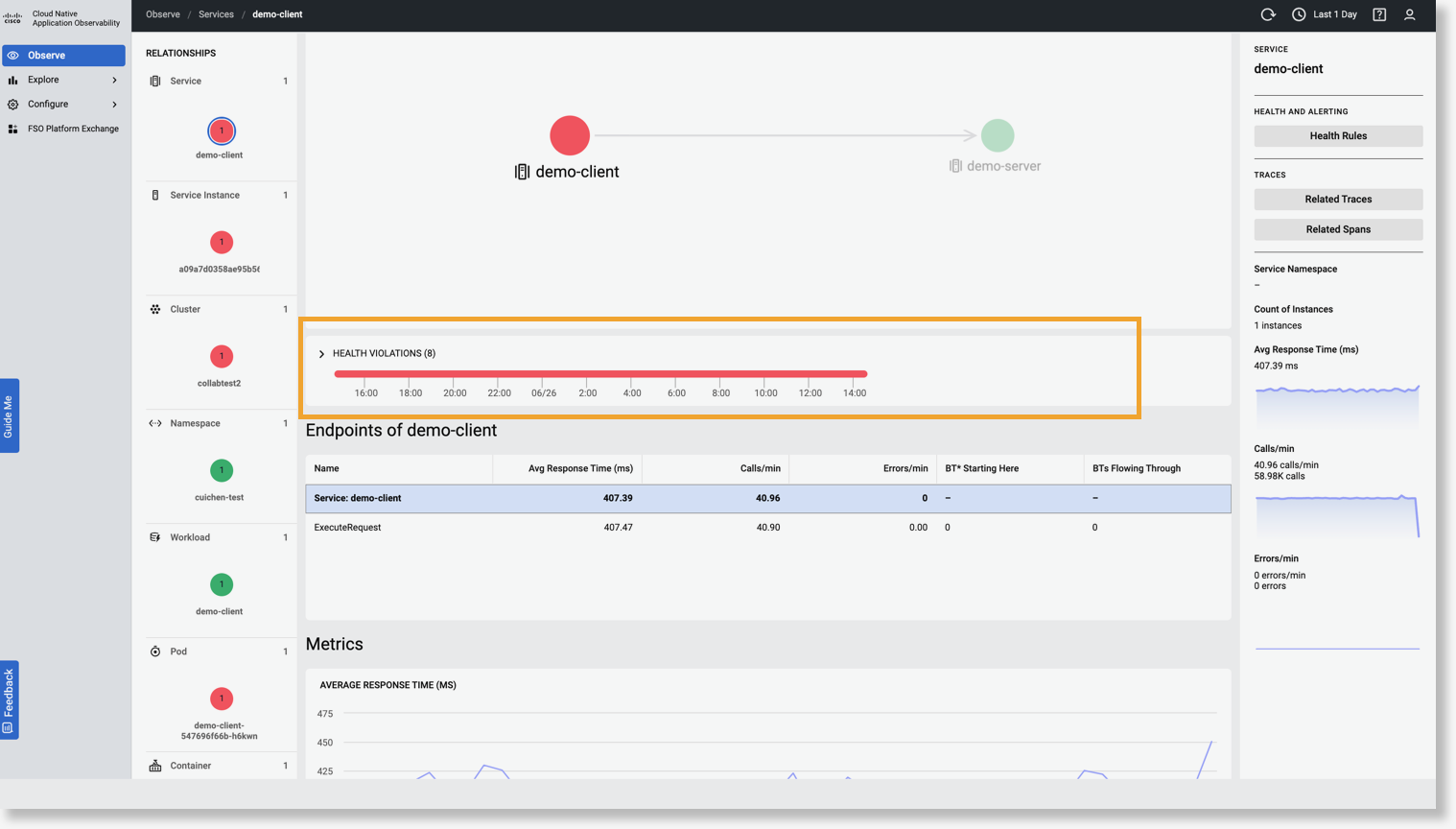
正常性違反のタイムラインを表示
正常性違反タイムラインで、選択したエンティティまたは正常性ルールの正常性違反の詳細を表示できます。正常性違反タイムラインにアクセスするには:
- [Observe] ページで、必要な期間を選択し、使用可能なドメインからエンティティタイプを選択します。たとえば、アプリケーション パフォーマンス モニタリング ドメインでは、エンティティタイプ [Services] を選択できます。
- [List] ビューから、エンティティ名をクリックします。選択したエンティティに対応する正常性違反、エンドポイント、メトリック、およびログの詳細が表示されます。
- [Health Violations (n)] セクションを展開して、選択したエンティティに関連付けられているすべての違反している正常性ルールのリストを表示します。
違反しているメトリックの表示
[Health Violations (n)] セクションで、正常性ルールをクリックして、関連する違反メトリックを表示します。[Violating Metrics] チャートは、正常性違反の詳細をすばやく調べるのに役立つベースラインとしきい値をグラフィックで表示します。単一のメトリックしきい値が定義されている正常性ルールの場合、チャートにはしきい値が表示されます。ベースラインが使用されている正常性ルールの場合、ベースライン、平均値、上部バンド、および下部バンドを表示できます。
標準偏差が選択されている場合、ベースラインの上部バンドと下部バンドは次のように計算されます。
Upper Band = Mean Value + (Factor * Standard Deviation)Lower Band = Mean Value - (Factor * Standard Deviation)
パーセント偏差が選択されている場合、ベースラインの上部バンドと下部バンドは次のように計算されます。
Upper Band = Mean Value + (Factor * Mean Value/ 100)Lower Band = Mean Value - (Factor * Mean Value/ 100)
正常性違反の検証
右側のパネルの [Health Violation Timeline] セクションと [Health and Alerting] セクションで、違反に関連するデータを表示できます。このデータは、違反している正確な状態またはメトリックを特定し、修正処置を講じるのに役立ちます。
[Health Violation Timeline ] には、選択したエンティティに関連付けられた違反している正常性ルールのリストが、重大または警告ステータスとともに表示されます。 赤は重大ステータスを示し
![]() 、黄色は 警告ステータスを示します
、黄色は 警告ステータスを示します![]() )。正常性ルール名
)。正常性ルール名![]() はタイムラインの上に表示されます。 違反のタイムライン と正常性違反の開始時刻
はタイムラインの上に表示されます。 違反のタイムライン と正常性違反の開始時刻![]() が 下部に 表示されます。正常性違反の終了時刻の 表示 は選択したデータ収集期間によって異なります
が 下部に 表示されます。正常性違反の終了時刻の 表示 は選択したデータ収集期間によって異なります![]() 。
。
詳細を表示するには、正常性ルールを選択します。次の [Violation Details![]() ] が右側のパネルに表示されます。
] が右側のパネルに表示されます。
- 正常性ルール name
- 違反メトリック
- エンティティ名
- 違反メトリックの平均値
- 開始日と時刻
- 進行中の違反の期間
- 違反のステータス(オープンまたはクローズ)
サービスを選択すると、[Health Violation Timeline] に異常検知ステータスの詳細が表示されます。
違反データの番号付きの詳細を表示するには、次の図を参照してください。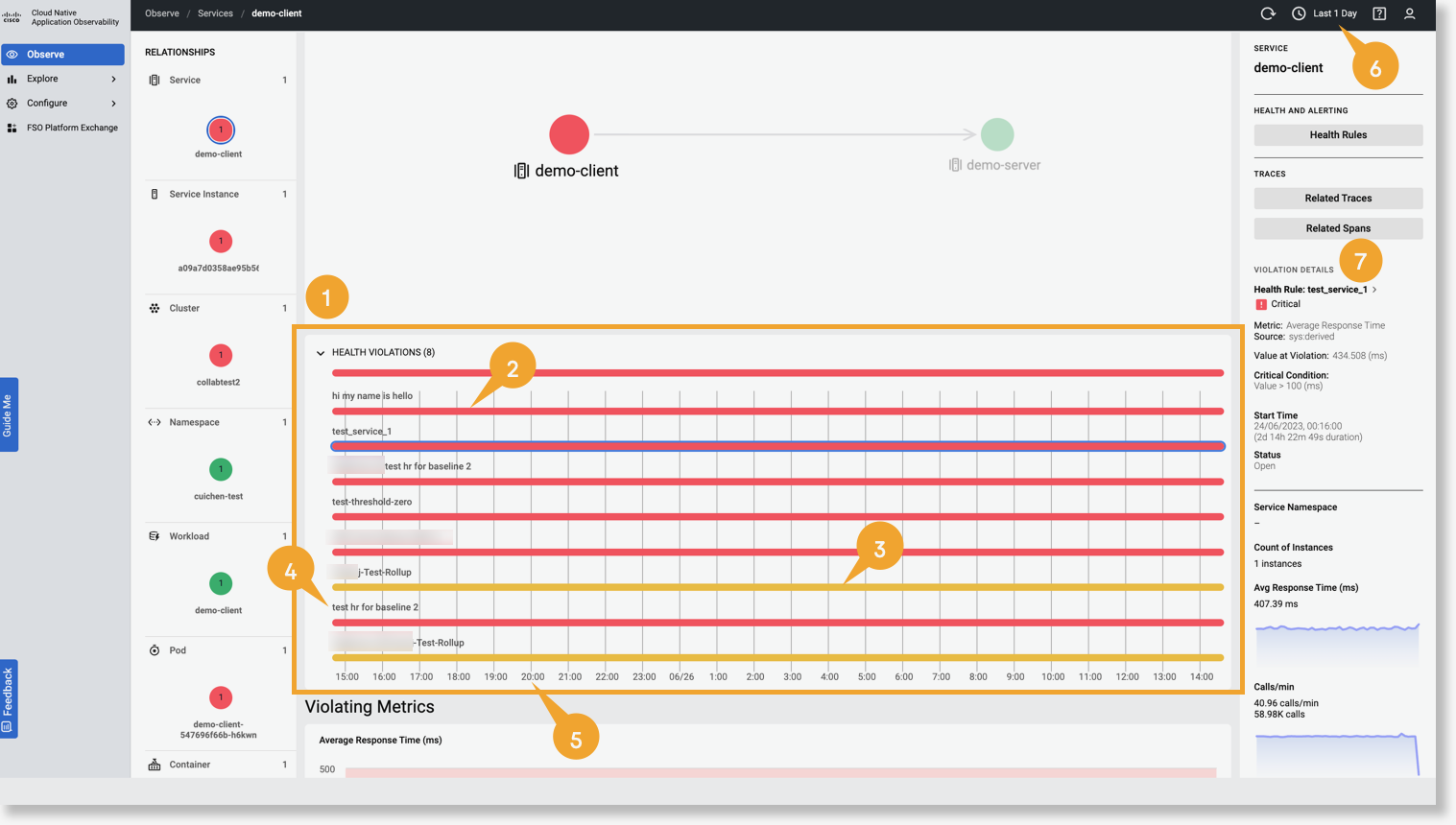
複数の正常性ルールを持つエンティティの正常性はどのように決定されるか
エンティティを監視するために複数の正常性ルールを構成できます。エンティティに複数の正常性ルールを構成した場合、パフォーマンスが最も低い正常性ルールによってエンティティの正常性が決まります。
正常性ルール違反の詳細を表示する
右側のパネルの [Health and Alerting] セクションにある [Health Rules] ボタンには、選択したエンティティの全体的なステータスが表示されます。これは![]() 、エンティティが正常でなく、エンティティに関連付けられた 1 つ以上の正常性ルールに違反していることを示しています。すべての正常性ルールの正常性ステータスを表示するには、[Health Rules] をクリックします。エンティティに関連付けられているすべて正常性ルールのリストが、正常性ステータスとともに表示されます。パフォーマンスが最も低い正常性ルールが、複数の正常性ルールを持つエンティティの正常性ステータスを決定します。次のアイコンは、正常性ステータスを示しています。
、エンティティが正常でなく、エンティティに関連付けられた 1 つ以上の正常性ルールに違反していることを示しています。すべての正常性ルールの正常性ステータスを表示するには、[Health Rules] をクリックします。エンティティに関連付けられているすべて正常性ルールのリストが、正常性ステータスとともに表示されます。パフォーマンスが最も低い正常性ルールが、複数の正常性ルールを持つエンティティの正常性ステータスを決定します。次のアイコンは、正常性ステータスを示しています。
 :正常性ルールに違反していて、重大な状態にあることを示します。修正処置が必要な場合があります。
:正常性ルールに違反していて、重大な状態にあることを示します。修正処置が必要な場合があります。  :正常性ルールが不明な状態にあることを示します 不明 。条件を決定的に評価するのに十分なデータがない場合、正常性ルールは不明な状態になります。
:正常性ルールが不明な状態にあることを示します 不明 。条件を決定的に評価するのに十分なデータがない場合、正常性ルールは不明な状態になります。 :正常性ルールに違反していて、警告状態にあることを示します。
:正常性ルールに違反していて、警告状態にあることを示します。 :監視対象のメトリックが期待される範囲内で実行されていることを示します。
:監視対象のメトリックが期待される範囲内で実行されていることを示します。
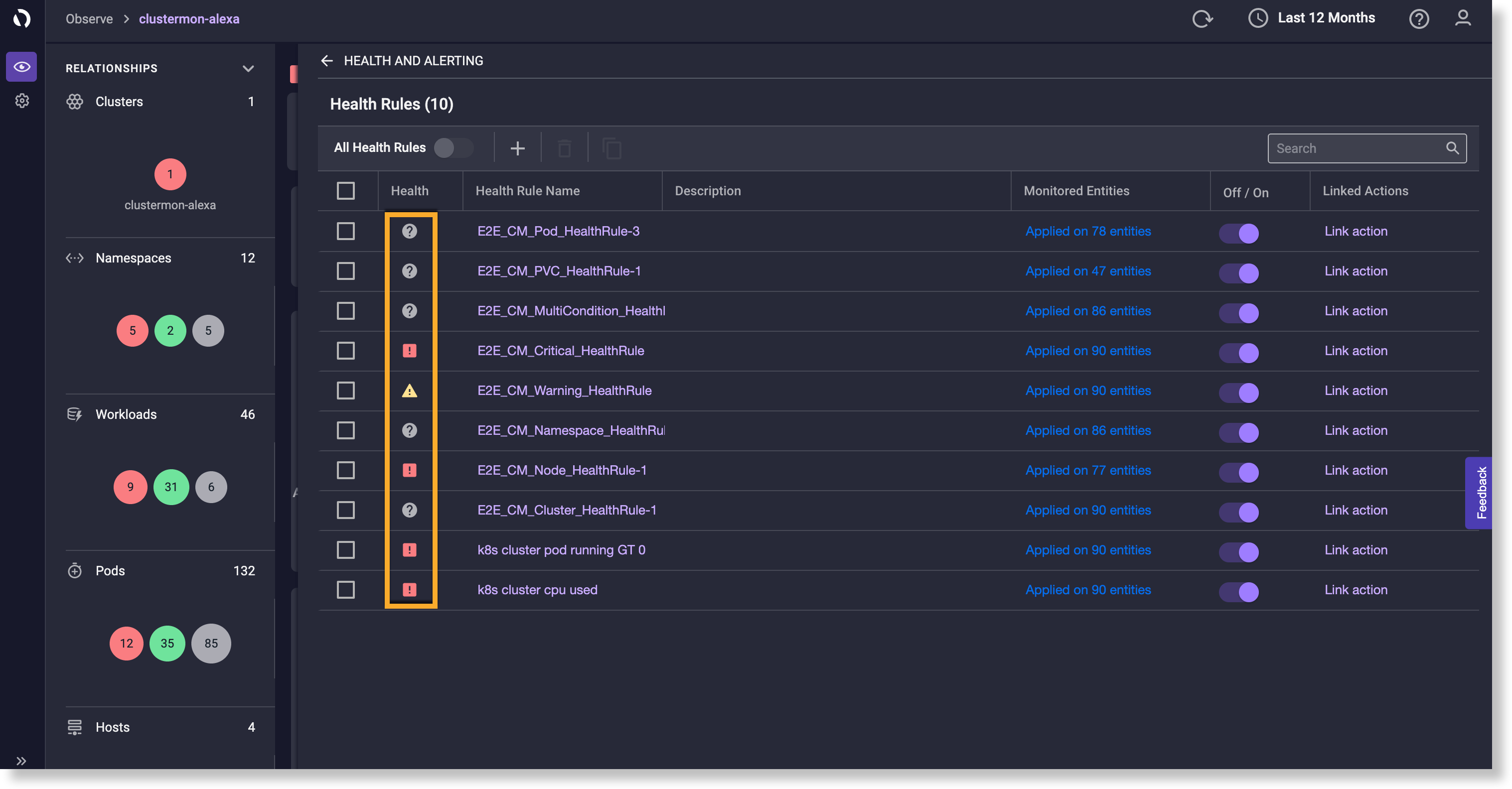
このリストには、次のような他の正常性ルールの詳細も表示されます。
- モニター対象オブジェクトの数 。
- 正常性ルールの評価が有効になっている。
- 正常性 ルールにリンクされたアクション。
正常性ルールの有効/無効 正常性ルール
正常性ルールリストの正常性ルールの評価を有効または無効にすることができます。エンティティに関連付けられた 1 つの正常性ルールまたはすべての正常性ルールの評価を有効または無効にすることができます。正常性ルールを無効にすると、再度有効にするまで、その正常性ルールの評価は一時停止されます。
監視対象オブジェクトのステータスの表示
正常性ルールに関連付けられている [Applied on 'n' objects ] をクリックして、 すべての監視対象オブジェクトのリストを表示します。監視対象の各オブジェクトの正常性ステータスは 表示 オブジェクトの隣に表示されます。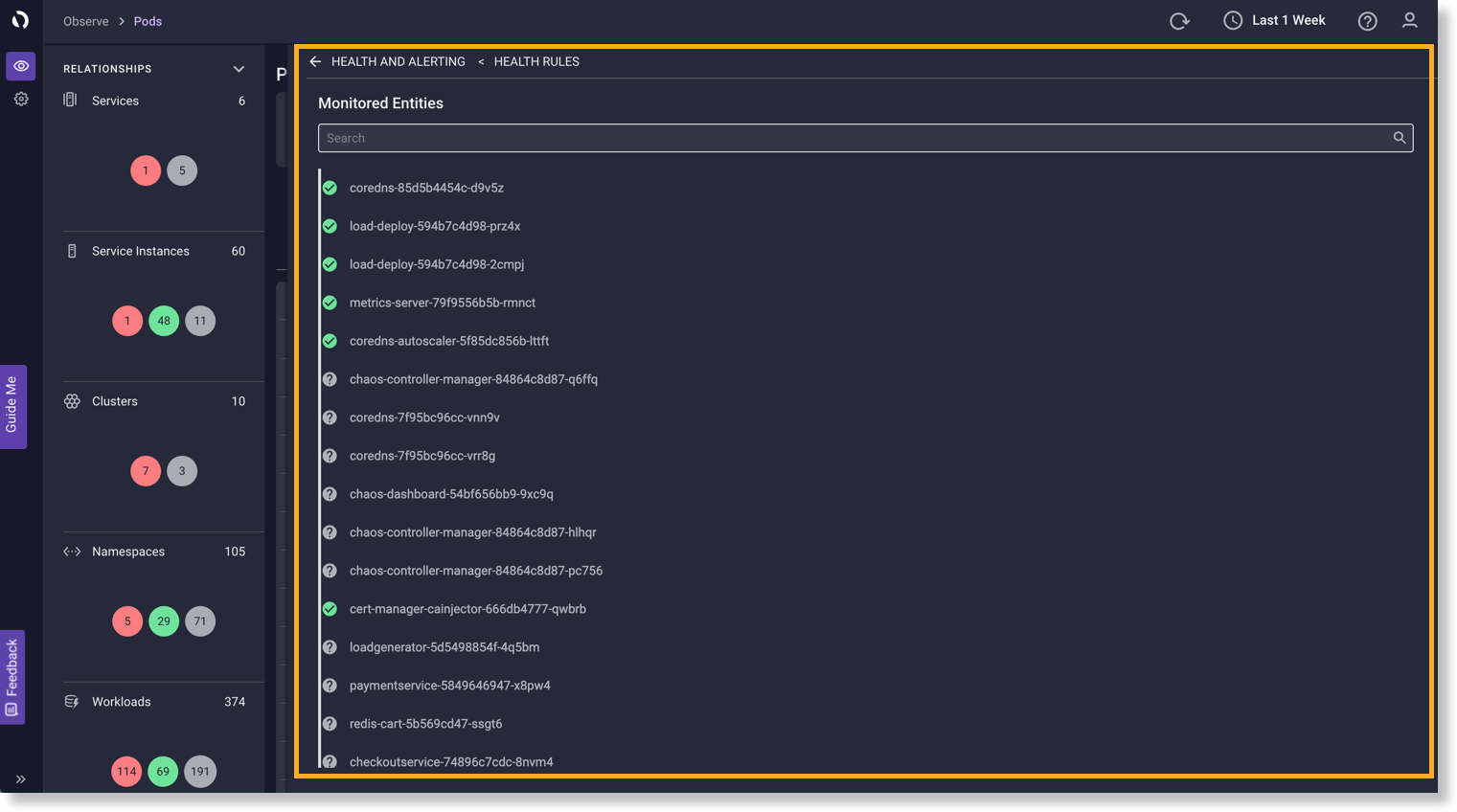
正常性違反によりトリガーされたアクションの追加/更新
[削除 正常性ルールに関連付けられたリンクアクション[ ] をクリックします。[Edit Health Rule] ウィザードが表示されます。必要に応じてアクションを追加または更新します。これらのアクションは、正常性ルールに違反したときにトリガーされます。詳細は、 「正常性ルールの編集」を参照してください。
正常性ルールにリンクする前に、アクションを作成する必要があります。詳細は、 「アクション」を参照してください。
異常検知
Cisco Cloud Observability異常検知は、アプリケーションのすべてのサービスが許容可能なパフォーマンス制限内で実行されているかどうかを自動的に判断します。機械学習機能を使用して、サービスの待機時間、エラー、スループットを継続的に監視し、異常な動作を識別します。これにより、アプリケーション パフォーマンスの問題の平均検出時間(MTTD)を短縮できます。
[Observe] > [Application Performance Monitoring] > [Services] からサービスを選択して、そのサービスで検出された異常の詳細を表示します。[Health and Alerting] セクションで [Anomaly Detection] の横にあるステータスごとに色分けされた記号は、サービスの全体的なステータスを示しています。
- :検出された異常が重大な状態であることを示します。修正処置が必要な場合があります。
- :検出された異常が不明な状態であることを示します。確定的に評価するのに十分なデータがない場合、異常は不明な状態になります。
- :検出された異常が警告状態であることを示します。
- インジケータが表示されない場合は、サービスが期待される範囲内で実行されていることを示します。
選択したサービスと他のサービスとの関係をフローマップまたはリストで表示できます。
異常検知は、アプリケーションのすべてのサービスに対してデフォルトで有効になっています。機械学習がアプリケーションのサービスでモデルトレーニングを行うには 48 時間かかります。[Configure] > [Anomaly Detection] をクリックして、すべてのサービスのモデル トレーニング ステータスとその他の詳細を表示します。「モデルトレーニング」を参照してください。
モデルトレーニングが完了すると、検出された異常を表示して監視し、修正処置を講じることができます。詳細については、「異常のモニタリング」を参照してください。