Download PDF
Download page KPI Metrics in Right-Click Dashboards.
KPI Metrics in Right-Click Dashboards
To diagnose a network element, right-click and select View Metrics. You can troubleshoot these network elements:
- Tier – The performance chart (top left) shows the rate or application performance outliers on the relevant nodes (Errors and Slow/Very Slow/Stalled Calls) and the Key Performance Indicators for all connections used by those nodes (Errors and PIE).
- Network Link – The performance chart (top left) shows the rate of Performance Impacting Events for all member connections of that link.
- Network Connection – You can troubleshoot a connection from the Connection Explorer or from the Connections tab in a link popup.
You can troubleshoot a transaction from a Transaction Snapshot.
- You can right-click an application flow and select View Network Metrics.
- You can also drill down to a node where a transaction delay/stall/error occurred and access the Network tab.
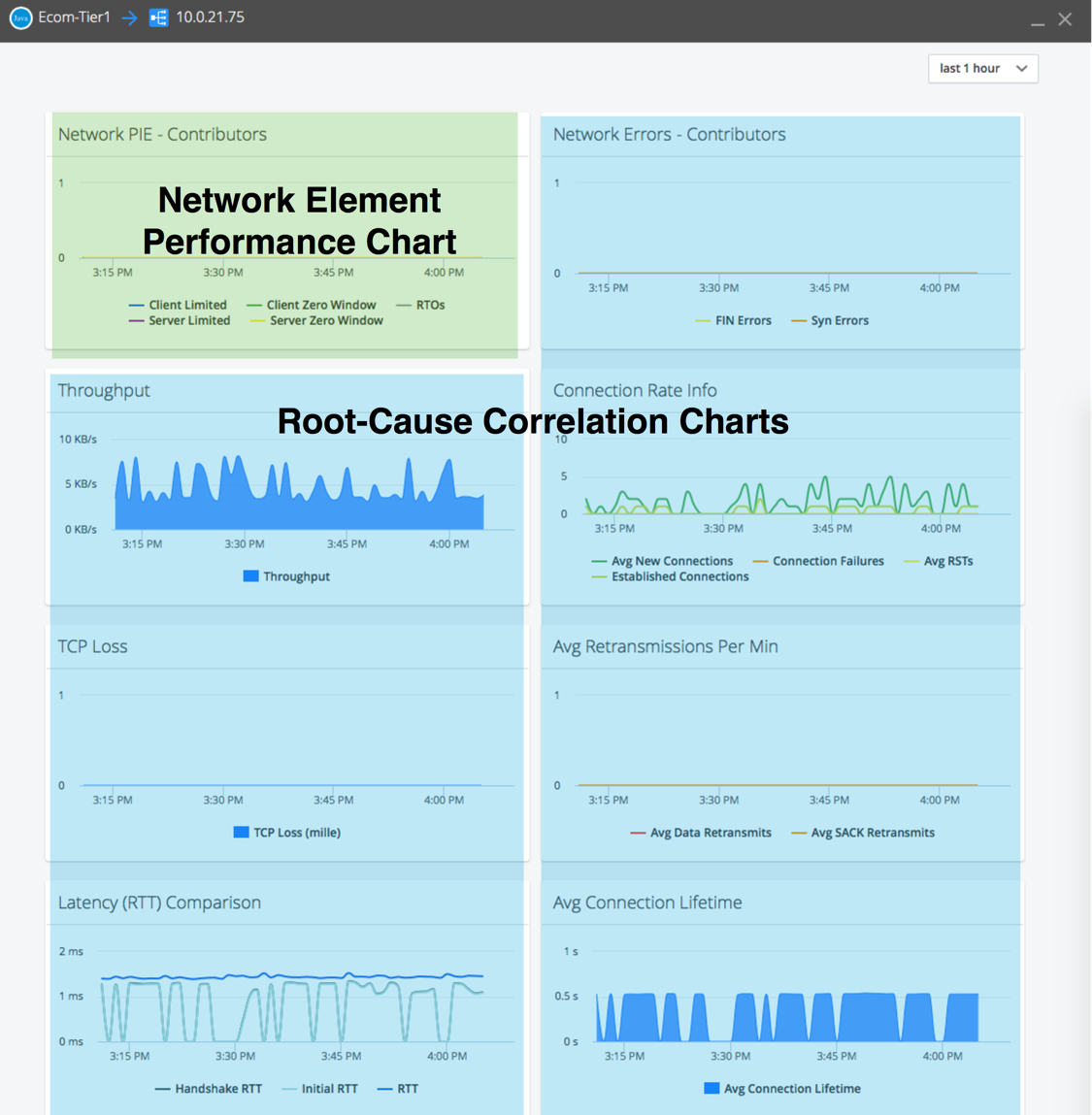
To troubleshoot a tier, link, or connection in the Network Dashboard, right-click the network element and select View Metrics. The top-left chart in the dashboard shows the overall network or network/application performance of the element. To troubleshoot the element, search for correlations between the performance chart (top left) and the other charts on the page.
Tip
To best highlight metric spikes and variations, you can switch between the linear and logarithmic scale in each chart. Click the settings button (top-right corner of the chart) to switch between scales.
Right-Click Chart Descriptions
| Chart | Description | Default Monitoring Mode |
|---|---|---|
Network Impact on Transactions (Tiers) | This chart highlights the possible impact of Performance Impacting Events on the app-transaction outliers (Transaction Errors and Slow, Very Slow, and Stalled Calls shown in the Transaction Scorecard). If you see spikes in transaction outliers and correlated spikes in PIE or errors, this indicates that the network is affecting application performance. Search for correlated spikes in the other charts to identify specific issues and root causes: connection errors, packet loss, re-transmissions, high-latency connections, and so on. | KPI |
Host Stack KPIs | Interface errors indicate issues on the node's physical interfaces. See Node Metrics in Network Dashboard and Metric Browser. TCP Wait sockets can result in significant delays or errors for the application, or service, that relies on that socket. Many simultaneous WAIT sockets can prevent applications and services from creating new connections. | KPI |
Network PIE - Contributors | Use Performance Impacting Elements (PIE) to identify the location of actual or potential bottlenecks:
| KPI |
Network Errors - Contributors | Use this chart to identify network errors that can affect application performance:
| KPI |
Throughput | Traffic throughput for the application of interest on the network element. This chart measures application payload data only; TCP, IP, and other packet headers are excluded. | KPI |
Connection Rate Info | Spikes in this chart, that coincide with spikes in slows calls or applications errors, indicate a possible issue with how the application is using TCP.
| KPI |
TCP Loss (mille) | The number of packets lost (sent but not received) per 1000 packets sent. "Per mille" is a percentage with one additional digit of precision. TCP detects lost packets and retransmits each lost packet until it receives an ACK (acknowledgment) from the peer. Spikes in TCP Loss indicate that the network is over utilized. | KPI |
Retransmissions per Minute |
| KPI |
Latency (RTT) Comparison | This chart compares the average TCP round-trip times (RTTs) for different types of packet request and responses.
| KPI |
Connection Lifetime | TCP is most efficient when using long, stable connections. Connection setups and teardowns are very time-consuming and resource-intensive. The more short-term connections are generated, the worse TCP performance will be because most of the time is spent creating connections and because "Slow-Start" in TCP optimal TCP bandwidth is not achieved. | KPI |