Download PDF
Download page 正常性ルール.
正常性ルール
正常性ルールでは、お使いの環境で正常または想定内のオペレーションであることを示すパラメータを指定します。たとえば、ホストに対しての CPU Utilization です。正常性ルールを作成して、1 つのエンティティまたはエンティティのグループを監視できます。「エンティティまたはエンティティのグループを監視する正常性ルールの作成」を参照してください。
正常性ルールの表示
設定されている正常性ルールのリストを表示するには、[Configure >] [Health Rules] をクリックします。カッコ内の数字は、設定されている正常性ルールの合計数を示します。[Description] 列には、正常性ロールアップの詳細が含まれます。このリストには、次のような他の正常性ルールの詳細も表示されます。
- 正常性ルール名
- 正常性ルールによって監視されるエンティティタイプ
- 説明
- 監視されるエンティティの数
- 正常性ルールにリンクされたアクション
- 正常性ルールの作成日時
- 正常性ルールの最終編集日時
- 正常性ルールの評価ステータス
検索ボックスを使用して、正常性ルールを名前で検索します。最初の列のチェックボックスを使用して、次のことを行う正常性ルールを選択します。
- すべての正常性ルールの正常性の評価を有効にする
- 1 つ以上の正常性ルールを削除する
- 正常性ルールのコピーを作成する
正常性違反
health violation は、正常性ルールによって監視されているエンティティのパフォーマンスが、ルールによって設定された条件に違反した場合に発生します。正常性の状態は、重大、警告、通常、NA、および不明で表されます。「正常性ルール違反の詳細を表示する」を参照してください。
エンティティの正常性ステータスが変わると、正常性ルール違反のイベントが発生します。正常性違反の例:
- Violation Started: Warning
- Violation Started: Critical
- Violation Upgraded: Warning to Critical
- Violation Downgraded: Critical to Warning
- Violation Continues: Warning
- Violation Updated: Warning
- Violation Continues: Critical
- Violation Updated: Critical
- Violation Ended: Critical to Normal
- Violation Ended: Warning to Normal
- Violation Cancelled: Warning
- Violation Cancelled: Critical
エンティティの正常性ステータスと正常性違反は、[Observe] ページに表示されます。正常性違反に対して、HTTP リクエストアクションなどのアクションをトリガーできます。
エンティティタイプとエンティティ
正常性ルールが監視するエンティティタイプを選択できます。エンティティは、エンティティタイプのインスタンスです。たとえば、k8s: pod(Kubernetes 名前空間)はエンティティタイプであり、o2-k8s-monitoring-appdynamics-otel-collector-lg29c (Kubernetes ポッドインスタンス)は k8s:pod のインスタンスです。エンティティレベルで正常性ルールが評価されるときに、エンティティタイプの正常性ルールを定義することに注意してください。
個々のエンティティのパフォーマンスを監視したり、エンティティをグループ化し、それらの集計パフォーマンスを監視したりできます。「正常性の評価」を参照してください。
フィルタ
属性(A)、タグ(T)、または親エンティティタイプに基づいてエンティティのリストをフィルタ処理し、監視する必要のあるエンティティをフェッチします。選択したエンティティに応じて、属性キー、タグ、およびそれらの値のリストから選択できます。
属性は、エンティティに関連付けられたプロパティです。タグは、非常に動的で複雑なクラウド環境でのリソースの編成と検出可能性を向上させるメタデータです。属性とタグを使用すると、エンティティをすばやく識別し、問題の根本原因をトラブルシューティングできます。
属性とタグごとに、リストから複数の値を選択できます。各引数(属性またはタグ)に対して選択された値の少なくとも 1 つが true の場合、フィルタ式は true を返します。
複数の属性、タグ、または属性とタグの組み合わせを選択して、フィルタを適用することもできます。すべての引数(選択した属性とタグ)が true の場合、フィルタ式は true を返します。
同様に、親エンティティのリストも選択できます。演算子を指定することで、条件をさらに絞り込むことができます。
正常性ルールのエンティティの詳細を定義するときに、エンティティの集計(ロールアップ)正常性評価を構成した場合にのみ、親エンティティでエンティティをフィルタ処理できます。
正常性の評価
エンティティのパフォーマンスまたは正常性は、次の時点で評価されます。
- 個々のエンティティレベル(詳細):アラートは、サービスインスタンスなど、単一のエンティティのパフォーマンスに基づいてトリガーされます。「エンティティタイプとエンティティ」を参照してください。
親エンティティレベル(エンティティのグループの集約):アラートは、親サービスによってグループ化されたサービスインスタンスなど、エンティティのグループの集約パフォーマンスに基づいてトリガーされます。集計パフォーマンスは、選択したメトリックに基づいて計算されます。具体的に、たとえばアラートは、グループ化されたすべてのエンティティのパフォーマンスが低下した場合、つまりサービス内のすべてのサービスインスタンスのパフォーマンスが低下した場合にのみトリガーされます。

構成済みの集約(ロールアップ)正常性の評価パスのエンティティが欠落している場合、正常性ルールは評価されません。
正常性ルール評価スケジュール
環境に定義されたメトリックを取り込み、そのメトリックを使用して正常性ルールの評価を開始できます。正常性ルールは 1 分ごとに評価されます。デフォルトでは、すべての正常性ルールは有効になっています。
違反後の正常性ルール待機時間
正常性ルールの [Wait Time After Violation] では、正常性ルールの違反状況が続いている間に違反が生成される頻度をコントロールできます。重大または警告のステータスの正常性ルール違反があると、[Violation Open: Critical] または [Violation Open: Warning] イベントが生成されます。このイベントは、必要なアクションを開始するために使用されます。
オープンイベントが発生すると、1 分ごとに正常性ルールのステータスが評価されます。同じ違反が検出される場合、違反は同じステータスでオープンのままになります。対応する [Violation Continues: Critical] または [Violation Continues: Warning] イベントが生成される場合があります。
1 分ごとの Violation Continues イベントは、正常性ルールに対してノイズが多すぎる場合があります。[Wait Time after Violation] の設定は、継続する正常性ルール違反に対して、こうした Continues イベントが生成される頻度を抑制するために使用できます。デフォルトでは 30 分毎です。
Violation Continues Critical および Violation Continues Warning イベントを使用するには、デフォルトの [Wait Time after Violation] 値をご希望の頻度に調整します。
[Health Violations] セクションに表示される違反は、正常性ルール違反イベントがトリガーされる場合にのみ更新されます。
何らかの理由で、正常性ルールが評価されない場合(ポッドがレポートを停止した場合など)は、正常性ルールリストの右側のパネルにある [Current Evaluation Status] タブで、正常性ルールの評価ステータスが灰色の疑問符または Unknown とマークされます。[Wait Time after Violation] が経過するまで、現在の違反イベントは開いたままになります。待機時間が経過した時点で、違反イベントは閉じられ、新しいイベントがトリガーされ、ルールの正常性ステータス自体が Unknown として表示されます。
遅延メトリックの正常性の評価
Amazon CloudWatch サービスなどのサービスから取り込まれたメトリックは、ソース自体で遅延することがよくあります。場合によっては、遅延が無視できないほど長くなることがあります。これにより、観測されたタイムスタンプと取り込まれたタイムスタンプの間に時間のギャップが生じます。つまり、環境でイベントが発生してから Cisco Cloud Observability UI で報告されるまでに時間の遅延が発生する可能性があります。この時間の遅延は、Splunk AppDynamics 名前空間に依存します。次の表は、さまざまな Splunk AppDynamics 名前空間に対してメトリックが報告されることが予想される最大遅延時間を示しています。
| 名前空間 | おおよその時間の遅延 |
|---|---|
| K8 | 4 ~ 5 分 |
| APM | 4 ~ 5 分 |
| CNI | 10 ~ 15 分 |
正常性ロールアップ
エンティティの正常性を集計(ロールアップ)して、エンティティのグループの正常性を定義できます。これは、子エンティティがロールアップ関係によって親エンティティの正常性を定義できることを意味します。エンティティと親の間の正常性ロールアップ関係を定義できます。
たとえば、次の図に示すように、名前空間とクラスタ間の正常性ロールアップ関係を定義できます。名前空間の 40% が異常であると報告された場合、クラスタの正常性も異常として報告される必要があります。
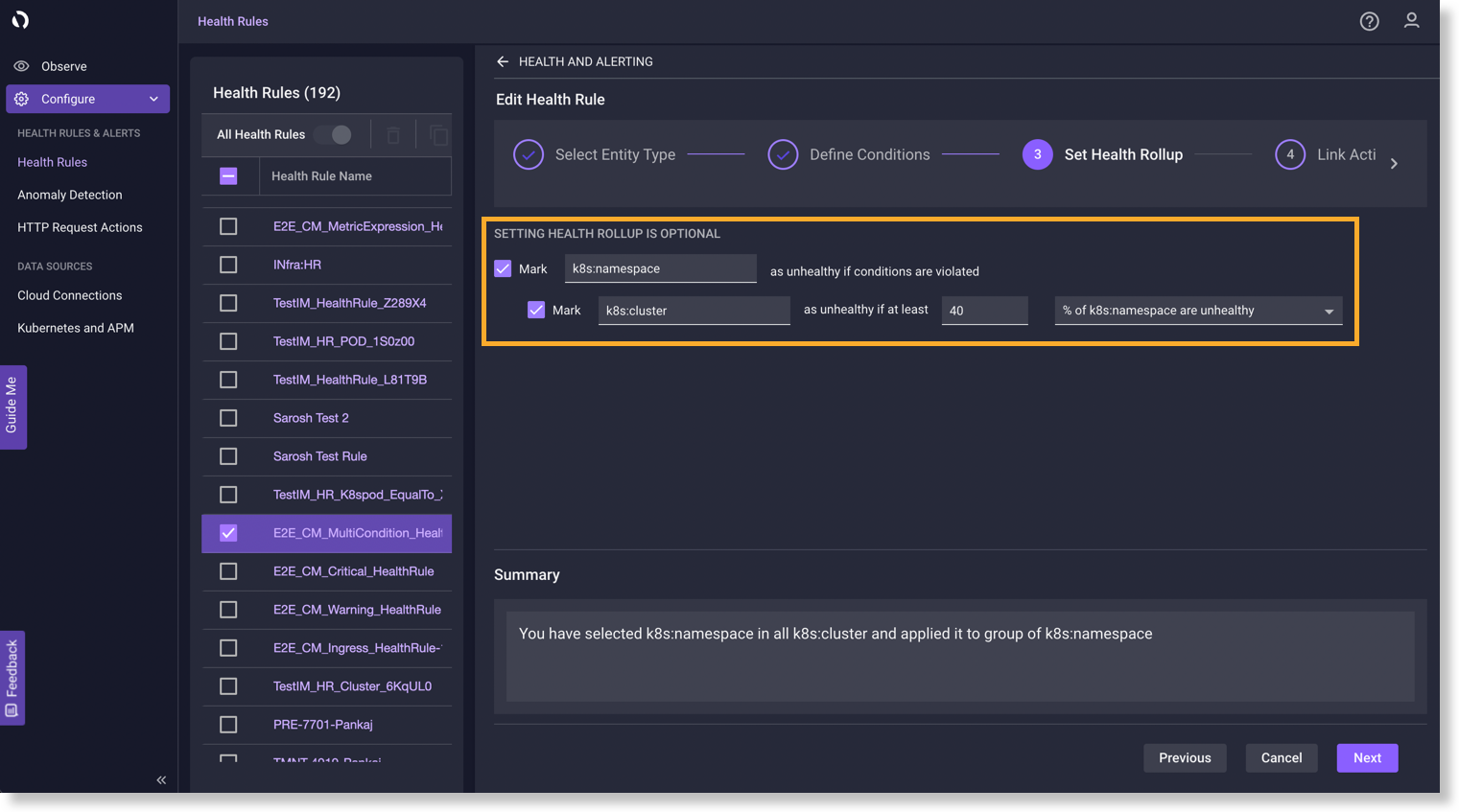
ただし、クラスタ内の名前空間には、正常、警告、重大などのさまざまな正常性ステータスがあります。前の図では、名前空間の 40% が異常で、ステータスが重大である場合、クラスタの正常性は重大として報告されます。警告数の計算の際 、重大ステータスの名前空間も警告数に含まれることに注意してください。次の表は、10 個の名前空間を持つクラスタのさまざまな正常性 ステータスを示しています。
| クラスタ内の名前空間の総数 | 重大ステータスの名前空間の数 | 警告ステータスの名前空間の数 | クラスタの正常性 |
|---|---|---|---|
| 10 | 3 | 2 | 重大数 = 3 警告数 = (3 + 2) = 5 10 の 40% = 4 クラスタの正常性はWarning |
| 10 | 2 | 3 | 重大数 = 2 警告数 = (2 + 3) = 5 10 の 40% = 4 クラスタの正常性はWarning |
| 10 | 4 | 4 | 重大数 = 4 警告数 = (4 + 4) = 8 10 の 40% = 4 クラスタの正常性はCritical |