Download PDF
Download page 正常性ルールの評価条件.
正常性ルールの評価条件
正常性ルールの条件は、特定されたメトリックの許容可能なパフォーマンス範囲です。条件により、[Warning] ステータスまたは [Critical] ステータスのメトリックレベルが定義されます。
条件は、選択されたベースラインに基づく 1 つ以上の静的または動的しきい値と、メトリックの現在値を比較するブールステートメントで構成されます。条件が当てはまる場合、その正常性ルールの違反になります。複数のしきい値で条件を評価するルールを構成できます。
静的しきい値は簡単です。たとえば、ポッドの Memory Utilization が 80%を超えているか? 80%? この条件は、Memory Utilization が 80% より大きい場合に true として評価され、 正常性 ルールに違反します。データをクエリするソースを選択することもできます。異なるソースからのメトリックには異なる粒度とプロパティがあるため、正常性の評価は選択したデータソースによって異なります。
動的しきい値は、ロールアップ ベースライン トレンド パターンに基づいて構築されたベースラインとの関連のパーセンテージ、またはベースラインの標準偏差に基づいています。
単一のメトリック値、または複数のメトリック値から構築された数式に基づいて、正常性ルールのしきい値を定義できます。
次に 正常性ルールの条件の例を示します。
- サービスに影響する準備状況/稼働状況の問題があるポッドがあるかどうかを知るには、次のように条件を定義します。
準備状況プローブステータス = ワークロードの 80% のポッドの場合 0
稼働状況プローブステータス = ワークロードの 30% のポッドの場合 0
- ポッドの再起動によってサービスが影響を受けるかどうかを知るには、次のように条件を定義します。
ワークロードの 80% のポッドの場合、ポッドの再起動が 3 より大きい
- 失敗または保留中のポッドについて知るには、次のように条件を定義します。
ワークロード全体の失敗したポッドの合計が 10% を超える
ワークロード全体の保留中のポッドの合計が 10% を超える
- 過去 15 日間の 1 分あたりのエラー数 ÷ 1 分あたりのコール数の値が 0.2 より大きい場合。
この例では単一の条件で 2 つのメトリックを組み合わせます。正常性ルールウィザードに埋め込まれている式ビルダーを使用して、相互依存の複数のメトリックからなる複雑な式に基づいた条件を作成できます。 (応答平均時間 > ベースライン OR 1 分あたりのエラー数 > ベースライン)AND(1 分あたりのコール数 > 定義されたしきい値)の場合。
次に、複数の条件を使用して正常性ルールを評価する例を示します。CUSTOM オプションを使用して、条件を評価するブール式を定義できます。
重大および警告の条件
条件は重大または警告に分類されます。
重大条件は警告条件より前に評価されます。重大条件と警告条件が同じ正常性ルールで定義されていると、警告条件は重大条件が真でない場合のみに評価されます。
重大条件と警告条件の構成手順は同じですが、これら 2 つのタイプの条件は別パネルで構成します。重大条件の構成を警告条件にコピーしたら(逆もまた同様)、メトリックを調整して区別をつけます。たとえば、[Critical Condition] パネルで、次のルールに基づいた重大条件を作成できます。
Request Countが 40 より大きい場合
[Warning Condition] パネルからその条件をコピーして次のように編集します。
Request Countが 35 より大きい場合
パフォーマンスの変化に伴い、高い方のしきい値まで下がると正常性ルール違反は警告から重大にアップグレードされ、パフォーマンスが警告のしきい値まで上がると重大から警告にダウングレードされます。
条件違反
メトリックレベルが許容範囲を超えると、条件に違反し、正常性ルールに違反します。違反の詳細は、[Observe] UI の [Health Violation] ペインに表示されます。このペインには、次の詳細情報が表示されます。
- 正常性ルール違反数
- リスト 違反しているすべての正常性ルールとそのステータスのリスト
- 違反の開始時刻
- 終了 時刻(データ収集の期間による)
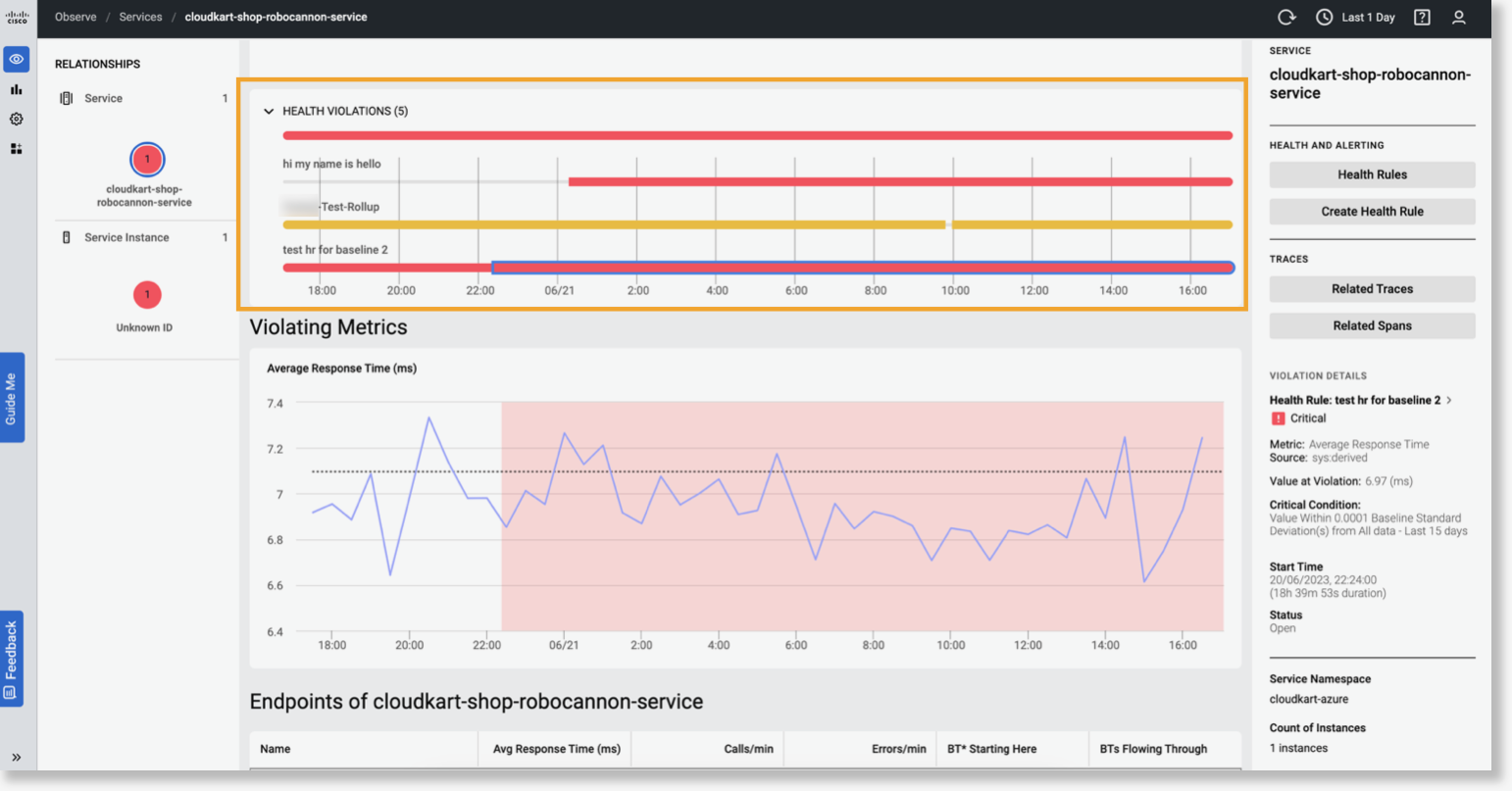
「正常性違反のタイムライン」を参照してください。
条件評価基準
正常性ルールに対して複数の条件を定義すると、定義した基準に基づいて評価されます。次のオプションを使用して、評価基準を定義できます。
- [All]:基準で定義されたすべての条件が
trueに評価されると、正常性ルールに違反します。 - [Any]:基準で定義されたいずれかの条件が
trueに評価されると、正常性ルールに違反します。 - [Custom]:複数の条件を持つブール式が
trueに評価されると、正常性ルールに違反します。
評価基準を設定する方法については、「条件評価基準」を参照してください。
次の表では例を使用し、基準に基づいて正常性ルールがどのように評価されるか、および違反と見なされるタイミングを説明します。
正常性ルールの設定 | 評価 | 例 |
|---|---|---|
| 単一の条件 | 条件は | 「平均応答時間」と定義されたベースラインを比較する正常性ルール。 |
ANY の評価基準を持つ複数の条件 | いずれかの正常性ルール条件が true に評価 | K8 ポッドの正常性をモニターする正常性ルールは、次のパフォーマンスメトリックのいずれかを測定することができます。
|
ALL の評価基準を持つ複数の条件 | すべての正常性ルール条件が | APM サービスの正常性をモニターする正常性ルールは、次のすべてのメトリックを測定します。
|
CUSTOM の評価基準を持つ複数の条件 | アクションの実行後に boolean 複数の条件が 条件は、 ビジネスに重大な影響が生じる前にアラートが迅速にトリガーされるようにするために、正常性ルールではブール式のすべての条件は評価されません。正常性ルールでは最初の条件の評価を開始し、式を true または false として確定的にマークできるようになるまで、次の条件を評価し続けます。評価によって式が違反すると判断されるとすぐに、アラートがトリガーされます。 | APM サービスの正常性をモニターする正常性ルールは、次の条件に基づいてパフォーマンスを測定します。
および
|
カスタムブール式
条件は、異なるメトリックを評価する複数のステートメントで構成されます。アプリケーションのパフォーマンスメトリックを評価するために、1 つの条件または複数の条件を定義できます。複数の条件を定義する場合は、ブール式を使用して評価基準を定義することができます。
ブール式を使用する boolean 利点は次のとおりです。
- さまざまなパフォーマンスメトリックをモニタするために、複数の正常性ルールを作成する必要性を軽減します。ブール式を使用すると、1 回の操作で複数の条件の複雑な基準を評価することができます。
- ブール式が適切に調整されるため、誤検出のアラートが減少します。
- 単純な条件名を使用する複雑な評価基準を利用して、正常性ルールを簡単に作成および維持できます。条件にA、B、C などという名前が付けられます。
ANDとOR演算子を使用して、非常に複雑なブール式を定義できます。
永続的しきい値
メトリック パフォーマンス データの一時的な上昇は偽のアラートの大きな原因です。永続的しきい値を使用すると、正常性ルールの感度レベルを定義し、偽のアラートの数を減らすことができます。評価タイムフレームでメトリック パフォーマンス データが定義されたしきい値を超える回数を定義し、違反を作成した後に、アラートをトリガーできます。
30 分以下の評価タイムフレームを定義している場合にのみ、条件の永続的しきい値を定義できます。
たとえば、CPU 使用率をモニターする場合、![]() しきい値の違反が 1 つのときの通知は受信しません。ただし、評価期間中にしきい値の違反が引き続き複数回
しきい値の違反が 1 つのときの通知は受信しません。ただし、評価期間中にしきい値の違反が引き続き複数回![]() 発生した場合は、通知が必要です。
発生した場合は、通知が必要です。
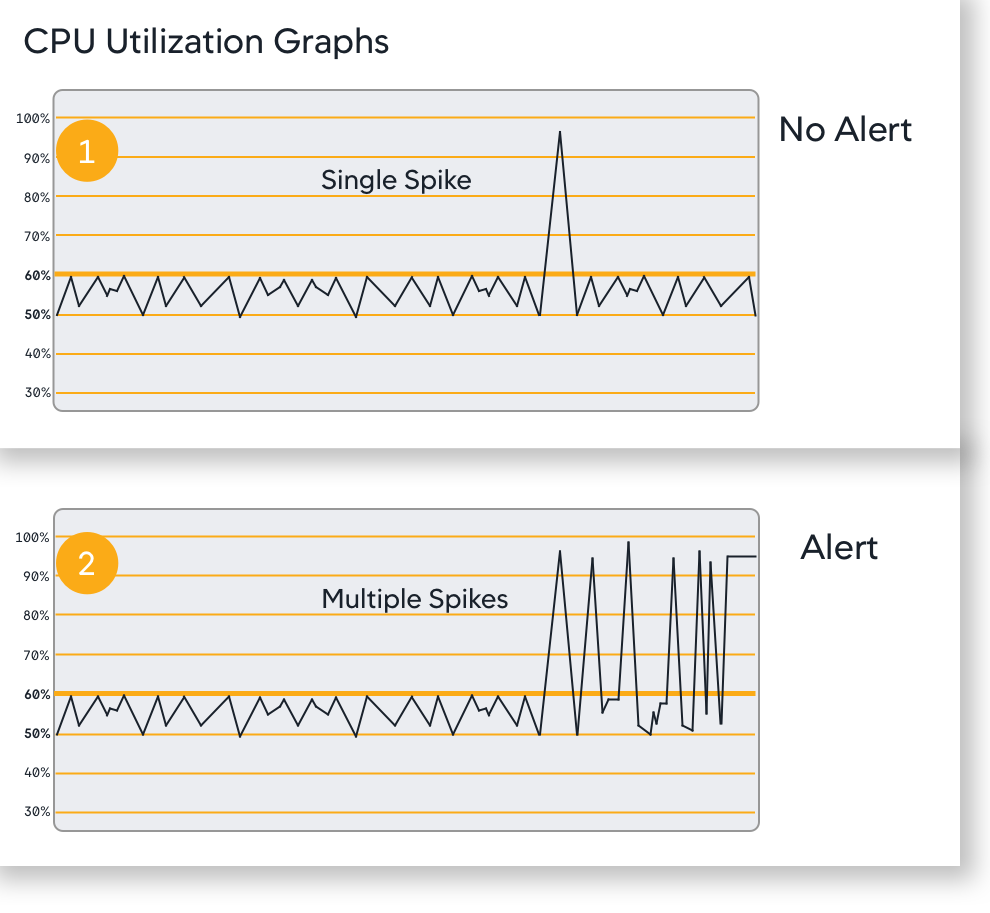
正常性ルール評価のタイムフレーム
正常性ルール評価タイムフレームは、正常性ルールを評価するために使用されるデータが収集される期間です。
異なる種類のメトリックにより、異なるデータの集まりを使用したより良い結果が得られます。データ収集期間を設定して、Cisco Cloud Observability が特定の正常性ルールを評価するときに使用するデータ量を管理できます。評価のタイムフレームは、1 ~ 120 分の範囲で定義できます。デフォルト値は 30 分です。[Use data from last] ドロップダウンで次の値を選択できます。
1、2、3、4、5、6、7、8、9、10、15、20、30、40、50、60、70、80、90、100、110、120
データが報告されていない場合の 条件の 評価方法
[Evaluate to true on no data] オプションは、条件をベースとした任意のメトリックが データを返さない場合の条件の評価を制御します。The データが返されない場合、条件は unknown と評価されます(デフォルト)。正常性ルールが true に評価されるすべての条件に基づいている場合、データが返されないと、正常性ルールがアクションをトリガーするかどうかに影響を与える可能性があります。
正常性ルールの評価のタイムフレームを定義すると、各データポイントの参照データが収集されます。タイムフレームで設定されたメトリックがデータの報告に失敗した場合、正常性ルール条件は次のように評価されます。
データがない場合は true と評価されます | 過去 y 分で違反が x 回発生した場合にのみトリガーされます。 | 条件の評価 |
|---|---|---|
| 有効 | 有効 | この条件は、評価のタイムフレームの各データポイントに対して評価されます。メトリックが特定のデータポイントのデータを報告できない場合、条件は たとえば、評価タイムフレーム、Y = 5 に、永続的しきい値、X = 3 を設定したとします。これは、条件を評価するために 5 つのデータポイントが必要であることを意味します。データは 4 つのデータポイントについて報告され、1 つのデータポイントについては報告されず、メトリックはしきい値を 2 回超えています。データが報告されない場合、条件はこのとき「true」と評価されます。 両方のオプションが有効になっている場合、ユーザーインターフェイス(UI)のイベントメッセージには、データがないために正常性ルール違反がトリガーされたかどうか、または永続性のしきい値に本当に違反したかどうかが指定されません。 |
| 有効 | 無効 | メトリックが評価期間中にデータポイントのデータを報告できない場合、条件は |
| 無効 | 無効 | 設定されたメトリックが評価期間中にデータポイントのデータを報告できない場合、条件は |