Download PDF
Download page 異常検知のインストールおよび設定.
異常検知のインストールおよび設定
異常検知サービスをインストールした後、異常検知を有効にする必要があります。異常検知を有効にすると、根本原因の自動分析も有効になります。
異常検知サービスのインストール
異常検知を使用するには、Kubernetes クラスタに異常検知サービスをインストールします。
異常検知の有効化
異常検知サービス をインストールした後、アプリケーションごとに個別に異常検知を有効にする必要があります。
- [Alert & Respond] の [Anomaly Detection] で、ドロップダウンから次のいずれかのアプリケーションを選択します。
- アプリケーション
- User Experience: Browser Apps
- User Experience: Mobile Apps
- [Anomaly Detection] を [ON] に切り替えます。
異常検知を有効にした後、異常検知と根本原因の自動分析が使用可能になるまでには、48 時間かかります。その間、アプリケーションの機械学習モデルがトレーニングされます。 - [Alert & Respond] > [Anomaly Detection] > [Model Training] を選択して、ビジネストランザクション、ベースページ、およびネットワークリクエストのトレーニングステータスを表示します(該当する場合)。
この表で、トレーニングステータスについて説明します。
| ステータス | 意味 |
|---|---|
| トレーニング中 | そのビジネストランザクション、ベースページ、ネットワークリクエストでモデルトレーニングが進行中です。 |
| 準備 | モデルトレーニングが完了し、ビジネストランザクション、ベースページ、ネットワークリクエストは正常です。 |
| 警告 | モデルトレーニングは完了していますが、ビジネストランザクション、ベースページ、ネットワークリクエストで、トレーニング期間中に 1 つ以上の警告レベルの異常が発生しています。 |
| クリティカル(Critical) | モデルトレーニングは完了していますが、ビジネストランザクション、ベースページ、ネットワークリクエストで、トレーニング期間中に 1 つ以上のクリティカルレベルの異常が発生しています。 |
| 使用不可 | モデルトレーニングが完了していないため、ビジネストランザクション、ベースページ、ネットワークリクエストで異常検知が表示されません。 |
モデルトレーニングは、異常検知が有効である限り継続されます。たとえば、ビジネストランザクションへのトラフィックがその日のトレーニングの妨げになるのに十分な時間中断された場合、異常検知は過去 7 日間のモデルを使用して機能し続けます。
サンプルサイズが非常に小さく、結果として得られるモデルが信頼できないため、1 分あたりのコール数(CPM)が非常に低いビジネストランザクション向けにトレーニングされた機械学習モデルはありません。
異常のモニタリング
ビジネストランザクション、ベースページ、およびネットワークリクエストの異常を表示およびモニターできます。
ビジネストランザクションに関連する異常を表示するには、次の手順を実行します。
- [Applications] > [Business Transactions] から、目的のビジネストランザクションを選択します。
- [Health] 列の [Warning] または [Critical] アイコンをクリックします。
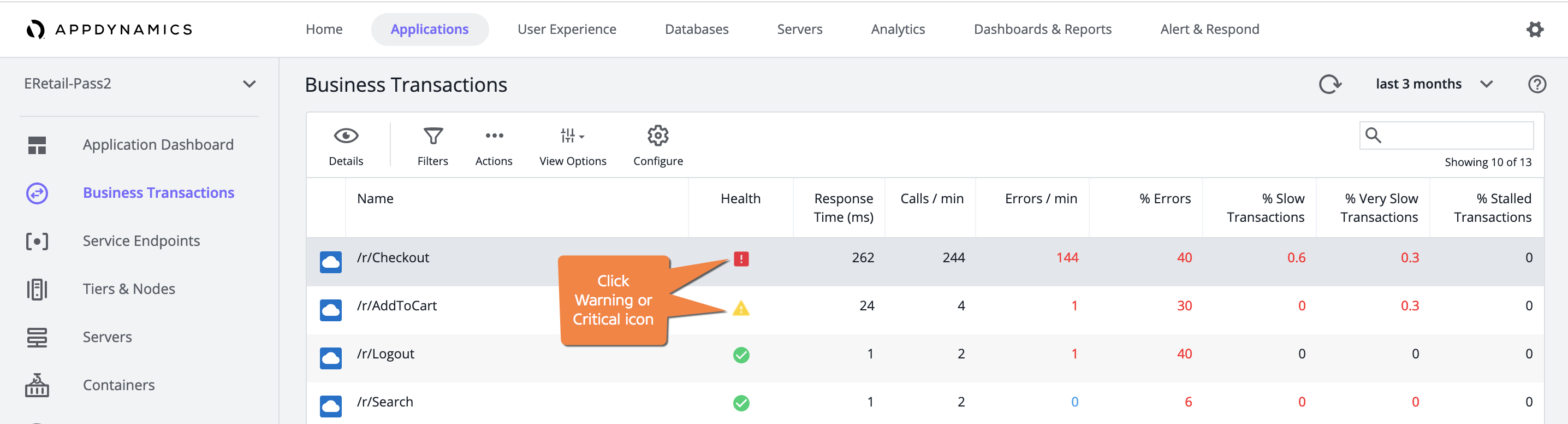
そのビジネストランザクションの正常性ルール違反と異常のリストが表示されます。
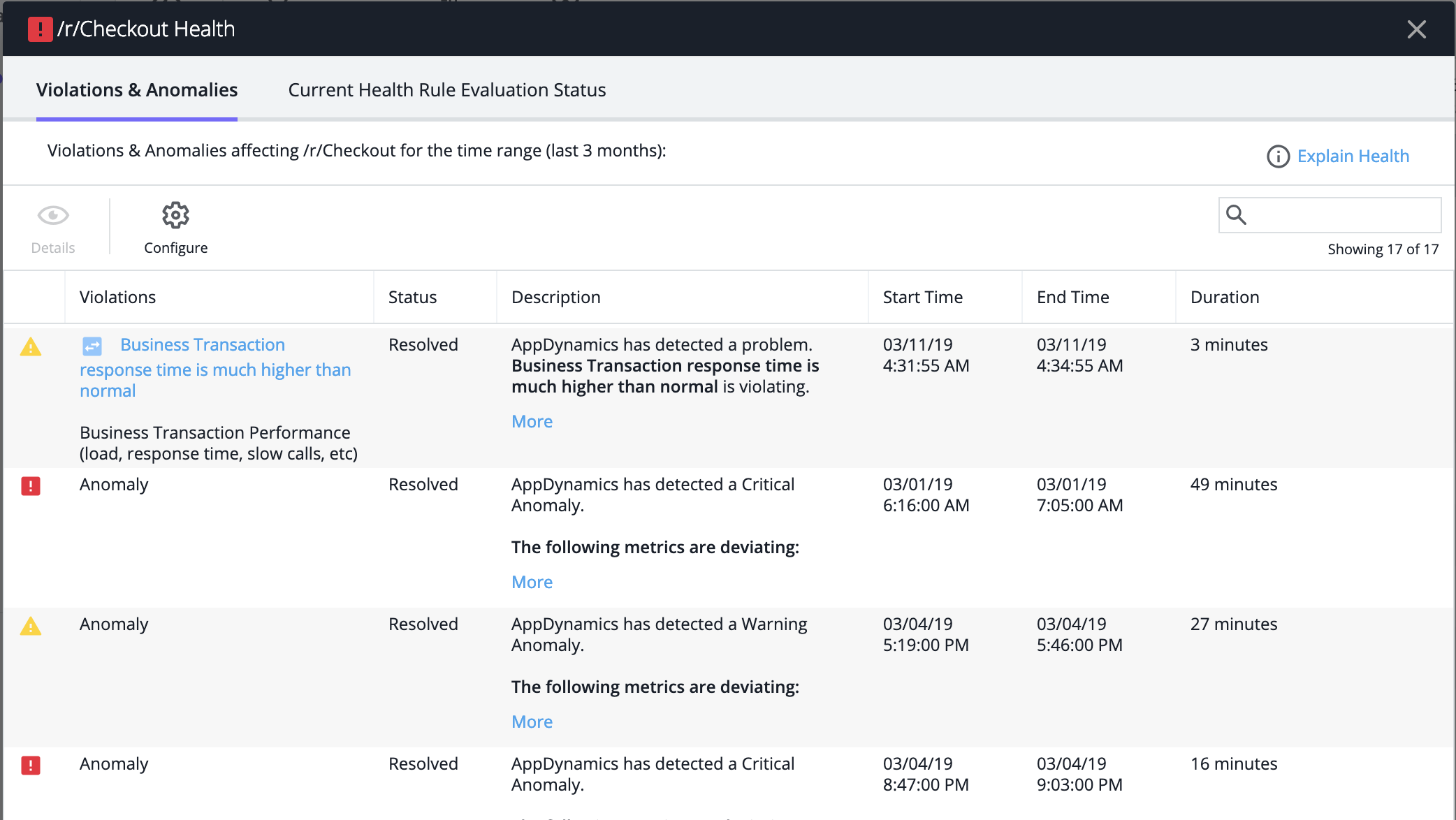
- 異常のリストは複数の方法で表示できます。異常のモニタリングには、Splunk AppDynamics の操作方法が反映されます。次のいずれかのオプションを選択し、根本原因の自動分析の結果が含まれる詳細表示を開きます。
- ツールチームのためにツールをセットアップして検証する場合は、
[Alert & Respond] > [Anomaly Detection] > [Anomalies] で異常の詳細を表示します。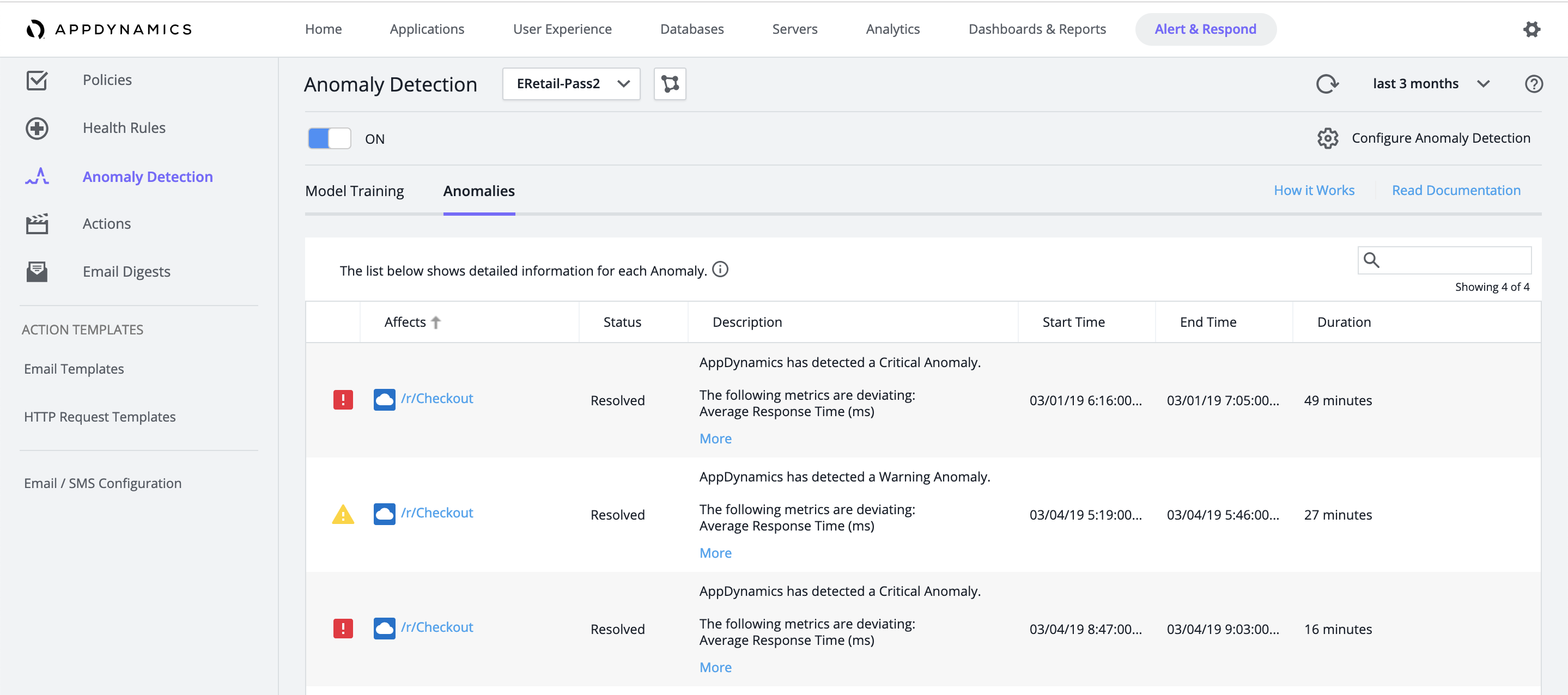
- アプリケーション運用チームのためにアプリケーションをモニターする場合は、次の手順を実行します。
- [Applications] > [Events] フィルタで、異常が含まれるように [Event Types] をフィルタリングします。
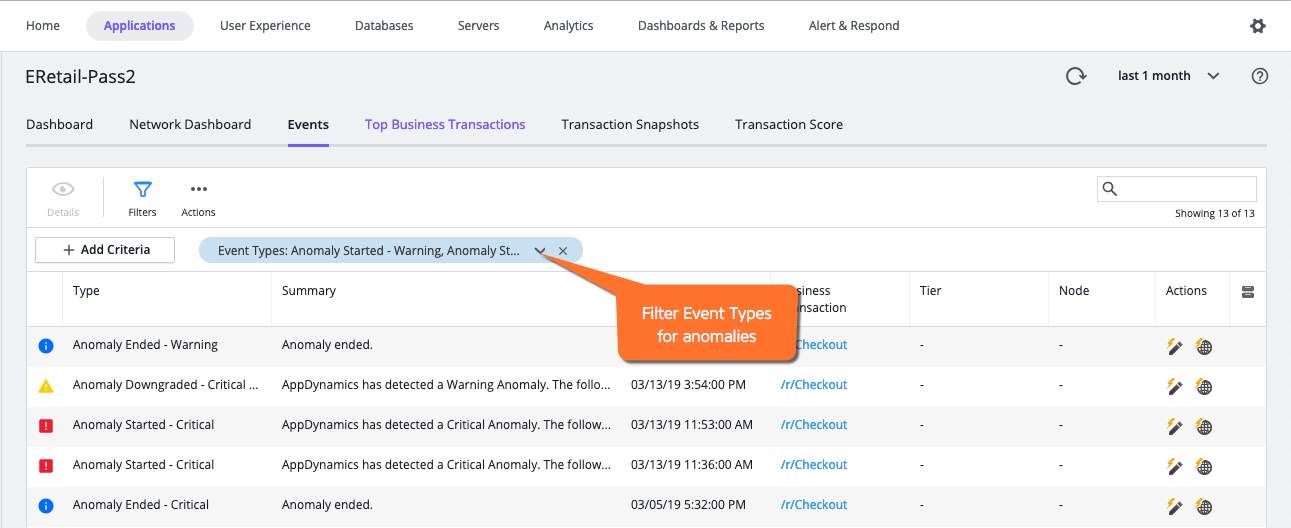
- [Applications] > [Events] フィルタで、異常が含まれるように [Event Types] をフィルタリングします。
- ツールチームのためにツールをセットアップして検証する場合は、
- [Applications] > [Troubleshoot] > [Violations & Anomalies] で、異常が含まれるように [Event Types] をフィルタリングします。
- [Applications] > [Troubleshoot] > [Violations & Anomalies] で、異常が含まれるように [Event Types] をフィルタリングします。
正常性ルールによってトリガーされるようポリシーを構成する方法と同じように、異常によってトリガーされるようポリシーを構成できます。
ブラウザアプリケーションに関連する異常を表示するには、次の手順を実行します。
- メインメニューから、[User Experience] > [Browser Apps] の順にクリックします。
- 目的のブラウザアプリケーションを選択し、[Details] をクリックします。
- 手順
- [Violation & Anomalies] をクリックして、選択したブラウザアプリケーションに関連付けられているすべての異常を表示します。
- [Events] をクリックして、すべての異常イベントを表示します。
モバイルアプリケーションに関連する異常を表示するには、次の手順を実行します。
- メインメニューから、[User Experience] > [Mobile Apps] の順にクリックします。
- 目的のモバイルアプリケーションを選択し、[Details] をクリックします。
- 手順
- [Health Rule Violations] をクリックして、選択したブラウザアプリケーションに関連付けられているすべての異常を表示します。
- [Events] をクリックして、すべての異常イベントを表示します。
異常検知の構成
デフォルトでは、異常検知により、アプリケーション内のすべてのビジネストランザクション、ベースページ、ネットワークリクエストで検知された異常についてアラートが発生します。ただし、異常検知を構成することで、異常を明らかにする対象を、指定した組み合わせのビジネストランザクション、ベースページ、ネットワークリクエスト、シビラティ(重大度)レベル、および検知感度にすることができます。この構成は、確認するアラートをより少なくし、より絞り込みたい場合に行います。
- [Configure Anomaly Detection] をクリックして構成ダイアログを開きます。

- ドロップダウンから目的のアプリケーションを選択します。
- アプリケーション
- User Experience: Browser Apps
- User Experience: Mobile Apps
- 異常検知を行う対象を、次の中から 1 つ選択します。
- ビジネストランザクションの場合:
- アプリケーション内のすべてのビジネストランザクション(これがデフォルトで選択されています)
- 特定のティア内のビジネストランザクション
- これらの指定されたビジネストランザクション
- 次の条件に一致するビジネストランザクション:
- 次で始まる
- 次で終わる
- 記載内容
- 次と等しい(Equals)
- 正規表現と一致
- リストにある
空ではない

また、NOT 演算子を選択して条件を反転することもできます。
- ベースページの場合:
- アプリケーション内のすべてのベースページ
- これらの指定されたベースページ
- 次の条件に一致するベースページ:
- 次で始まる(Starts With)
- 終わり(Ends With)
- 次を含む(Contains)
- 次と等しい(Equals)
- 正規表現と一致
- リストにある
空ではない(Is not empty)
また、NOT 演算子を選択して条件を反転することもできます。
- ネットワークリクエストの場合:
- アプリケーションでのすべてのネットワークリクエスト
- これらの指定されたネットワークリクエスト
- これらの指定されたモバイルアプリケーションのネットワークリクエスト
- 次の条件に一致するネットワークリクエスト:
- 次で始まる(Starts With)
- 終わり(Ends With)
- 次を含む(Contains)
- 次と等しい(Equals)
- 正規表現と一致
- リストにある
空ではない(Is not empty)
また、NOT 演算子を選択して条件を反転することもできます。
- ビジネストランザクションの場合:
- 次のシビラティ(重大度)レベルのいずれかを選択します。
- すべてのシビラティ(重大度)(警告とクリティカルの両方を含む)
- クリティカル
- 警告
[Detection Sensitivity] で、次のいずれかのレベルを選択します。
機密レベル 説明 High ビジネスに不可欠なサービスにこのレベルを使用して、環境内で問題が確実に検知されるようにします。より多くのアラートをトリガーしますが、統計の信頼性は低くなります。 中 このレベルは、ビジネスにとって重要だがクリティカルではないサービスに使用します。デフォルトでは、この感度レベルが選択されています。 低 ビジネスへの影響が少なく、アラートが多すぎるのを避けるために、このレベルを使用します。 非実稼働環境で異常検知をテストする場合は、[Yes, turn on test mode] を選択します。
テストモードでは、非実稼働環境での異常検知機能を評価できます。このモードでは、メトリックデータの収集が少ない場合でも、異常検知によってパフォーマンスの問題が正確に検知されます。開発環境またはステージング環境でテストモードを使用できます。
- [Save] をクリックして設定を完了します。