AppDynamics の異常検知および根本原因の自動分析という 2 つの機能は、アプリケーション パフォーマンス上の問題の平均解決時間(MTTR)を短縮するように設計されています。
異常検知は、アプリケーション内のすべてのビジネストランザクションが正常に実行されているかどうかを自動的に判断します。根本原因の自動分析は、異常検知によって明らかになった問題の根本原因を迅速に特定できます。
異常検知の仕組み
異常検知は、ビジネストランザクションの異常が発生した場合に機械学習機能を使用して、Mean Time to Detect(MTTD)を短縮します。特別に設計されたアルゴリズムが使用され、何も構成する必要はありません。異常検知アルゴリズムは次のように動作します。
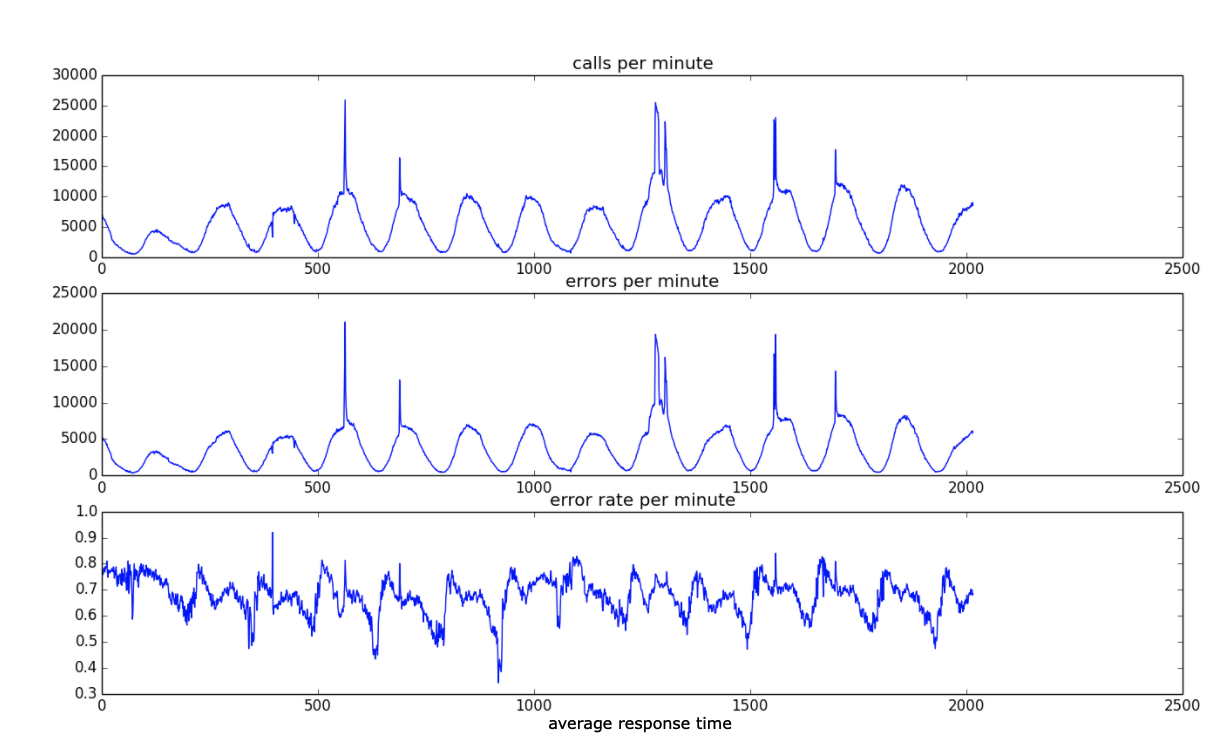
[Errors per minute](EPM)メトリックに異常な測定値が報告されているかどうかを検出します。
[Average Response time](ART)メトリックに異常な測定値が報告されているかどうかを検出します。
次に、アラートノイズを減らすように設計されたヒューリスティックを使用して、これらのメトリックの測定値から学習したデータを結合します。
異常検知では、収集するメトリックデータの正確性を確保するために、複数の手法が使用されます。
- 一時的なスパイクやデータがない期間は無視されます。
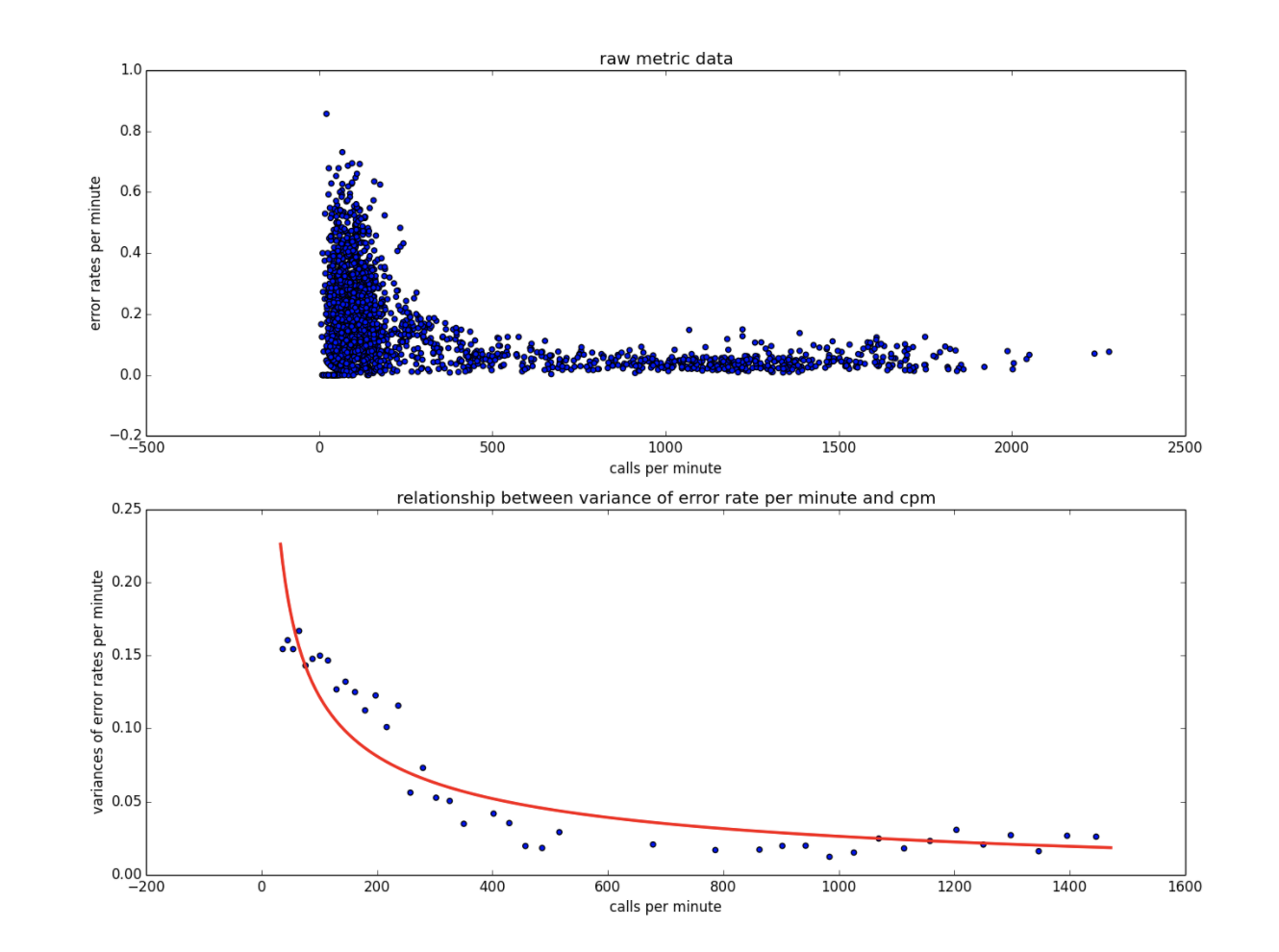
- メトリックデータが正規化されます。たとえば、EPM メトリックデータを判断する場合、[Calls per Minute](CPM)の対応する増加がない限り、スパイクが実際の問題を示しているとは限りません。EPM データ自体が有用でない可能性があるため、異常検知ではエラー率(EPM/CPM)が使用されます。
- 従来の季節的なベースラインは適用されません。代わりに、信頼性の高い結果を得るために、EPM と ART のバリアンスを CPM に関連付けます。
根本原因分析(RCA)とは
アプリケーションのエンティティに異常がある場合は、その理由を知る必要があります。異常検知では AI 機能が使用されて根本原因の自動分析が有効になり、アプリケーション内のすべてのエンティティの正常性をモニタし、すべての異常について疑わしい原因を表示することができます。疑わしい原因の確認または否定を簡単に行い、必要に応じて逸脱しているメトリックとスナップショットにドリルダウンすることができます。そのため、アプリケーションの異常の根本原因を迅速に特定できます。
RCA の仕組み
RCA は、問題の発生元を自動的に示すことで、平均識別時間(MTTI)を短縮します。RCA は、障害ドメインを識別するためのメトリックと、アプリケーション全体からのスナップショットおよびイベントを考慮して、疑わしい問題を見つけ出します。この包括的なアプローチは、次の 2 つの要素で実行されます。
- 障害ドメインの分離:システム内の問題の正確な場所の識別
- 影響を受けるコンポーネントの分析:影響を受けるコンポーネントを特定するための、ログ、スナップショット、トレース、インフラストラクチャなどの分析
異常検知と正常性ルールの違い
異常検知と正常性ルールの両方がアプリケーションのパフォーマンス上の問題を警告しますが、異常検知は正常性ルールを使用して取得することが困難な強力なインサイトを提供します。
| 異常検知 | 正常性ルール |
|---|
異常検知は機械学習を使用して主要なビジネス トランザクション メトリックの通常の範囲を検出し、これらのメトリックが予想される値から大幅に逸脱した場合に警告します。そのため、正常性ルールによって人手でキャプチャできるものよりも、幅広い範囲の問題を特定できます。 | 正常性ルールは手動で作成され、1 つ以上のメトリックを満たさなければならないという論理条件が適用されます。たとえば、[Average Response Time](ART)をモニタして、このメトリックが構成されたベースラインから外れているかどうかを確認できます。 |
| 異常に関するアラートを制限する場合を除き、異常検知では構成を必要としません。 | AppDynamics にはデフォルトの正常性ルール一式が用意されていますが、必要に応じて、期間、傾向、スケジュールを構成して追加の正常性ルールを手動で作成できます。 |
| 異常はビジネストランザクションに関連付けられます。 | 正常性ルールは、ビジネストランザクションやサービスエンドポイントなどの、すべてのエンティティに適用されます。 |
