Download PDF
Download page Tier Metric Correlator.
Tier Metric Correlator
Tier Metric Correlator を使用すると、階層内のすべてのノードの負荷とパフォーマンスの異常値を識別できます。コンテナまたはサーバで実行されるノードのクラスタで構成されている階層があるとします。すべてのノードが同じ負荷条件下で同じように動作すると想定します。このクラスタで異常値をどのようにモニタできますか。Tier Metric Correlator を使用すると、次の疑問に答えることができます。
- すべてのノードが予想されるパフォーマンスの範囲内で動作しているか、または一部のノードで異常値(低速コール、ストール、およびエラー)が発生しているか。
- どの時間枠で、およびどのノードでこれらの異常値が発生しているか。
- 異常値は特定のノードクラスタ(たとえば、カナリアリリースを実行しているクラスタ)に関連しているか。
- リソースの問題(高い CPU I/O やページングなど)がこれらの異常値に関係しているか。
- コールは階層内のすべてのノードに均等に分配されているか。
このページでは、次の 2 つの使用例について説明します。
- 階層メトリック相関を使用して、階層内のすべてのノード間でコールがバランスよく分配されているかどうかを迅速に特定する。
- 階層メトリック相関を使用して、カナリア展開シナリオをモニタしてトラブルシューティングする。この例では、ノードクラスタ間でパフォーマンスを簡単に比較する方法、トランザクションの異常値があるノードを特定する方法、およびリソースの問題がこれらの異常値を引き起こしているかどうかを判断する方法を示します。
主なコンセプト
トランザクションの異常値
メトリック相関の最初のステップは、階層のトランザクションの異常値(応答時間がその階層の正常の範囲を大きく逸脱した低速コール、非常に低速なコール、および停止したコールの数)を特定することです。トランザクションの異常値ヒートマップにより、これらの異常値のレートと階層内のすべてのノード間での異常値の分布を視覚化します。
ヒートマップは、追加ディメンションがある時系列グラフです。各棒の色の強さは、すべてのノードでの異常値の分布を示します。色合いが暗いほど、より多くのノードに異常値があります。グラフでは、棒の色がグレー(異常値が少ない)とオレンジ色(異常値が多い)のグラデーションとなっています。

ヒートマップを使用すると、階層内のすべてのノードのパフォーマンスの正常範囲と異常値を簡単に特定できます。この例では、すべてのノードが 2 つの範囲に分類されています。

このヒートマップでは、パフォーマンスメトリックがノードの 50% に対して著しく高い 2 つの時間枠が強調表示されます。

相関メトリック
相関メトリックヒートマップを使用すると、トランザクションの異常値と特定のリソースメトリックを相関させることができます。[Correlate Metrics] パネルを使用すると、対象のトランザクションの異常値に関連する(および関連しない)パフォーマンスメトリックを簡単に識別できます。この例は、次の 3 つのヒートマップを示しています。
- トランザクションの異常値
- 相関メトリック
- 非相関メトリック(異常値なし)

ノードとサーバのトラブルシューティング
一連のトランザクションの異常値を選択すると、[Selected Nodes] グラフと [Impacted Servers] グラフにより、階層内のすべてのノード間でのこれらの異常値の分布が示されます。これにより、これらの異常値が特定のノードクラスタに関連するかどうかを簡単に判断できます。円グラフをダブルクリックして、ノードまたはサーバのトラブルシューティングを行います。

ユースケースの例
負荷分散の比較
この例では、開発運用エンジニアが、トランザクションコールが階層内のすべてのノードに均等に分配されているか確認します。エンジニアが [Tiers & Nodes ] ビューにアクセスし、階層を右クリックして、[Correlate Metrics] を選択します。[Calls Per Minute] ヒートマップを確認することで、エンジニアはパフォーマンスの範囲が 1 分あたり 20 ~ 22 コールであることをただちに確認できますが、一部のノードでは、特定の間隔でレートが高くなっています。エンジニアは関連するロードバランサを調べ、簡単な設定ミスが原因で、デバイスがコールを特定の時間に不均等に分配していることを発見しました。ヒートマップを使用することで、軽微な問題がチームのミッションクリティカルなアプリケーションに大きな影響を与える前に、その問題を特定して修正できます。

カナリアデプロイテスト
開発運用エンジニアが、4 階層の e-コマースアプリケーションを担当しているとします。[Order] 階層には、バージョン 1.0 のサービスを実行する 5 つのノードがあります。エンジニアは、1 つのノードに「カナリア」(バージョン 1.1 のサービス)を展開しています。エンジニアはすべてのノードに 1.1 を展開する前に、このノードでパフォーマンスの低下が発生しているかどうかを判断したいと考えています。

エンジニアはコントローラを開き、目的のアプリケーションの [Tiers & Nodes] ビューにアクセスし、[Order] 階層を右クリックし、[Correlate Metrics] を選択します。Tier Metric Correlator が表示されます。
[Transaction Outliers] ヒートマップによって、一部のコールが異常([Errors]、[Slow Calls]、[Very Slow Calls]、または [Stalled Calls])であることが示されます。応答時間がその階層のパフォーマンスの範囲よりも大幅に高いものが異常です。

エンジニアの最初の疑問は、これらの異常が「カナリアノード」(ORD-N1)に関係しているかどうかということです。エンジニアはこれらの一連の異常をドラッグして選択します。[Node Distribution in Selection] 円グラフ(右)によって、すべての異常がカナリアノードに関連していることが示されます。明らかに、新しいコードは、古いコードと同様に実行されていません。
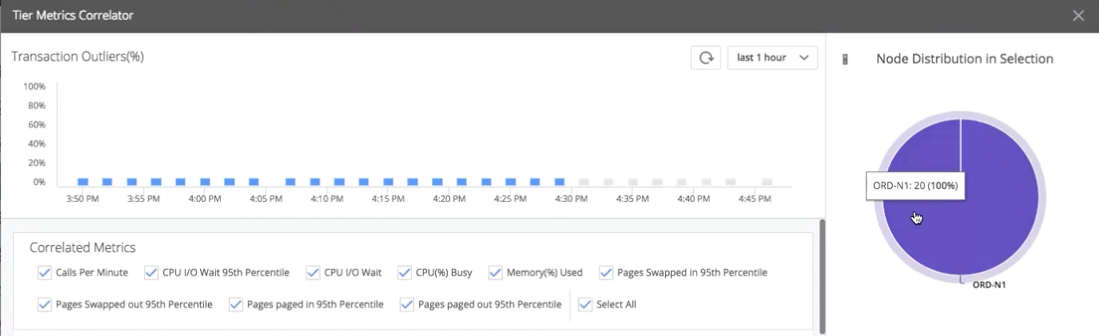
次の疑問は、リソースの問題が原因でこれらの異常が発生しているかどうかということです。エンジニアは [Correlated Metrics] ヒートマップを調べて、カナリアノードの異常に関係するメトリックを確認します。ほとんどのヒートマップは相関なしを示します。たとえば、[CPU Busy%] は、すべてのノードが 0 ~ 20% のパフォーマンスの範囲内に収まることを示しています。

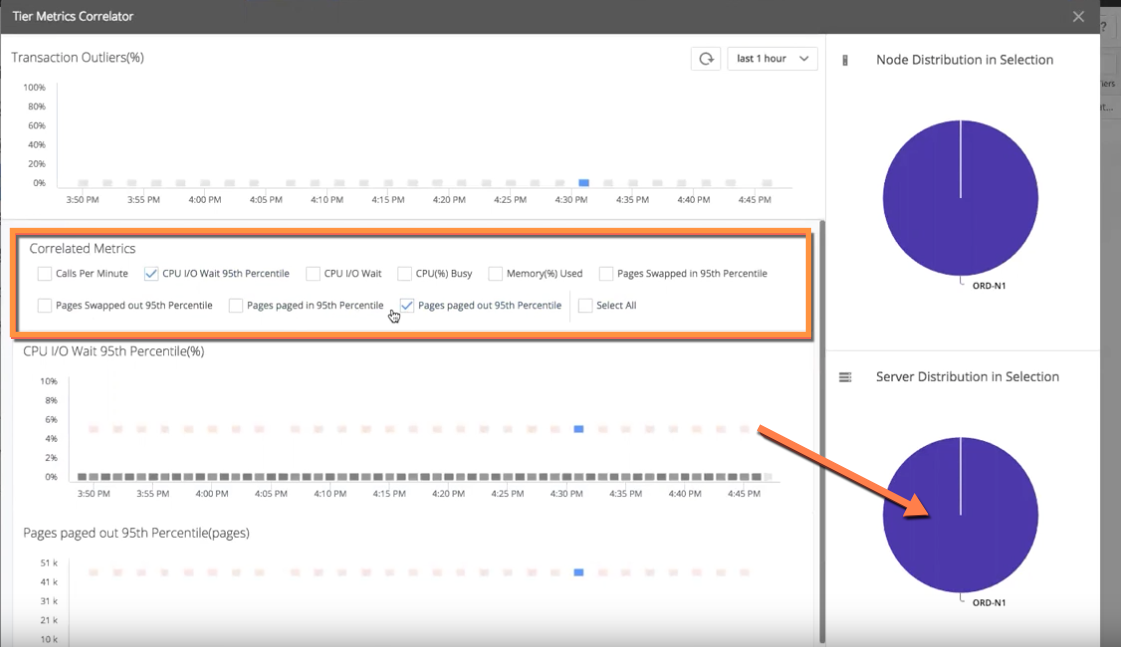
ただし、[CPU I/O Wait 95th Percentile(%)] ヒートマップは強力な相関を示しています。すべてのメトリックの異常がカナリアノードで発生していて、一方で他のすべてのノードはパフォーマンスの範囲内に収まっています。

また、[Pages paged out 95th Percentile (pages)] ヒートマップも、カナリアノードのトランザクションの異常との強力な相関関係を示しています。わずか数回のクリックで、カナリアノードのパフォーマンスが低下していること、ノードに CPU I/O の問題があること、および CPU I/O の問題がページングに関連していること(これはディスクの問題を示します)をただちに確認できます。

不要な情報を減らし、相関関係に注目するために、エンジニアは関係しないすべてのメトリックをオフにします。次のステップは、基盤となるサーバを調査してトラブルシューティングすることです。カナリアノードにドリルダウンするために、[Server Distribution in Selection] 円グラフ(右下)をダブルクリックします。
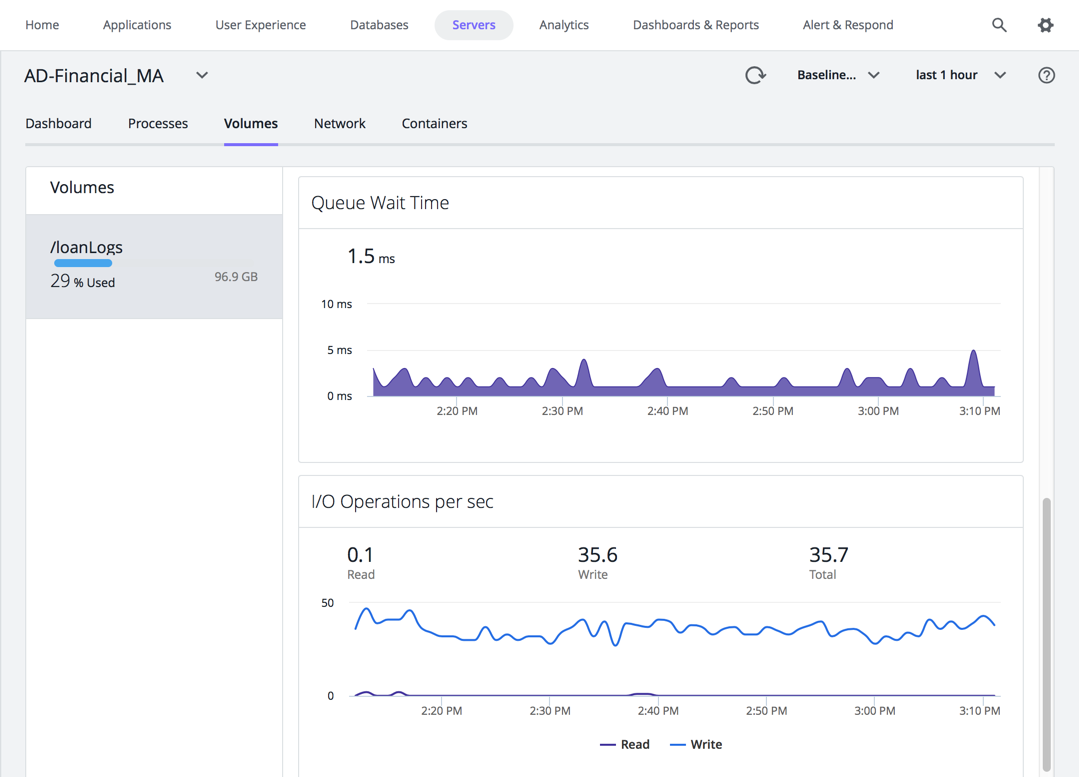
カナリアノードのサーバダッシュボードが表示されます。エンジニアが [Volumes] タブを選択し、I/O 操作とキューの待機時間に多くの急増があることを発見します。カナリアコードを階層全体に展開する準備はまだできていないと判断したため、カナリアコードを再調査し、問題を修正し、再テストする必要があります。
Tier Metric Correlation の有効化
コントローラでアカウントごとに Tier Metric Correlation を有効にします。
SaaS コントローラを使用している場合は、AppDynamics サポートに連絡してください。
オンプレミスのコントローラを使用している場合は、次の手順を実行します。
rootユーザのパスワードを使用して、コントローラの管理コンソールにログインします。http://<controller host>:<port>/controller/admin.jsp- [Accounts] ページにアクセスし、この機能を有効にするアカウントを選択します。
- アカウンティング設定で [Add Property] を選択し、次のように追加します。
ENABLE_SIM_HEATMAPS= true
パーセンタイルメトリックを関連付けるために、コントローラとマシンエージェントの両方で、パーセンタイルメトリックのレポートを有効にする必要があります。デフォルトでは、レポートはコントローラでは無効になっていて、エージェントでは有効になっています。
- コントローラでレポートを有効または無効にするには、コントローラの管理コンソールにログインし、
sim.machines.percentile.percentileMonitoringAllowedプロパティを設定します。次を参照してください。Controller Settings for Standalone Machine Agents - エージェントでレポートを有効または無効にするには、
<machine_agent_home>/extensions/ServerMonitoring/conf/ServerMonitoring.ymlファイルを開き、percentileEnabledプロパティを設定します。次を参照してください。サーバの可視性のためのマシンエージェントの設定
ワークフローの説明
次の手順は、ワークフローの説明の概要を示しています。
目的のアプリケーションの [ Tiers & Nodes] ビューにアクセスします。
- 階層を右クリックして [Correlate Metrics] を選択します。Tier Metric Correlator が表示されます。
- 階層のトランザクションの異常
 ([Slow]、[Very Slow]、[Stalls]、または [Errors] のフラグが付けられているコール)を特定します(「ビジネストランザクションのパフォーマンスのモニタ」を参照)。
([Slow]、[Very Slow]、[Stalls]、または [Errors] のフラグが付けられているコール)を特定します(「ビジネストランザクションのパフォーマンスのモニタ」を参照)。 - カーソルをドラッグして目的の異常を選択します。右側の円グラフには、ノードとサーバ別にこれらの異常の分布が示されます。
- 異常の相関メトリック
 を特定します。非相関メトリック
を特定します。非相関メトリック  のチェックボックスをオフにします。
のチェックボックスをオフにします。 - 異常が発生しているノード
 とサーバ
とサーバ  を特定してトラブルシューティングします。円のスライスをダブルクリックして、ダッシュボードビューを開きます。関連するメトリックを使用して、トラブルシューティングを行うことができます。
を特定してトラブルシューティングします。円のスライスをダブルクリックして、ダッシュボードビューを開きます。関連するメトリックを使用して、トラブルシューティングを行うことができます。
