This page provides use case examples for alert and response features:
Define health rules that apply to specific tiers or nodes. Instead of choosing specific nodes, you can trigger a rule when more than a certain percentage of nodes are unhealthy, say 20%.
Start a diagnostic action for a business transaction.
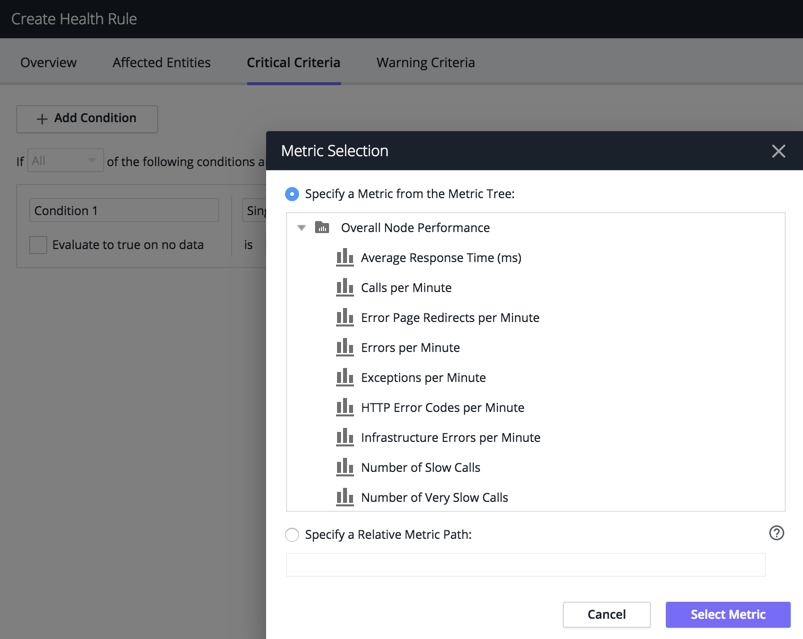
Alert when an app agent stops reporting to the Controller. Create a node health rule based on the value of the Availability metric reported by the agent. If Availability is less than one, the agent is not reporting.
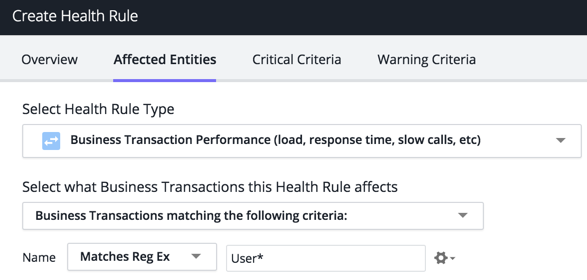
Alert when the 95th percentile metrics for specific business transactions reach a certain value. You want to apply this rule only to business transactions with names beginning with User.
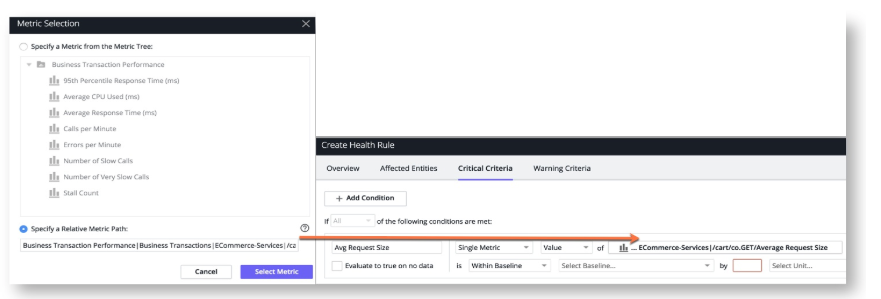
You can generalize a health rule by specifying a relative metric path, rather than a specific metric. The health rule is evaluated for each of the affected business transactions. Use a relative metric path when you need to evaluate a single metric for multiple entities.
You have a large operation with several development teams, each responsible for a different service. You create a health rule for one service and then copy it. Then create different policies in which you can pair each copy of the health rule to an alert addressed to the appropriate team.
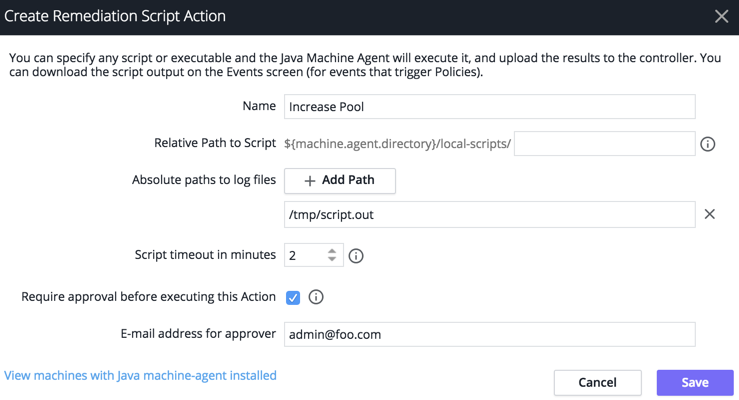
Start a script to change the size of the connection pool. You have an application that performs well for a normal load. However, peak loads can cause the application to slow. During peak load, the AppDynamics not only detects the connection pool contention but also allows you to create a remediation script that can automate increasing or decreasing the size of the connection pool. You can require human approval to run this script or just configure it to automatically execute when it is triggered. Create a runbook and associate it with a policy so that it will run when the connection pool is exhausted.
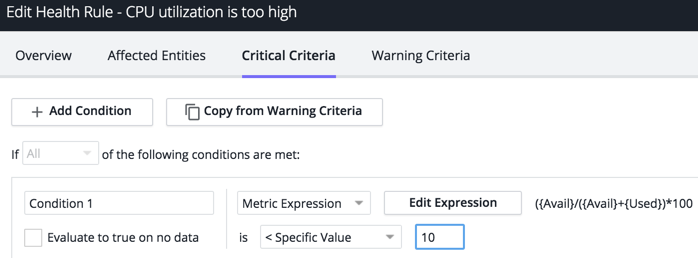
Alert when the available disk volume is low. Use an expression including two metrics – available and used disk space – to be alerted when disk volume is low.
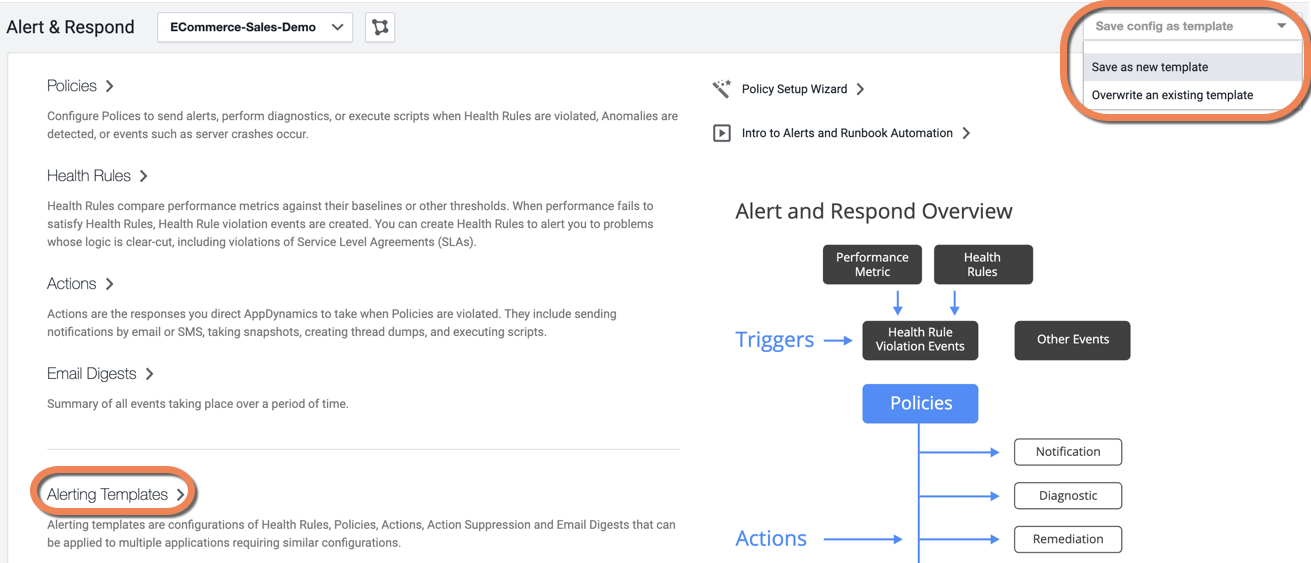
When configuring Alert and Respond features for an application, you can select Save Config as Template to save the application configuration as a template. You can then apply this template to multiple applications to ensure consistency. To make a global configuration change, you can update the template selecting Overwrite an existing template and then re-apply it to the required applications.
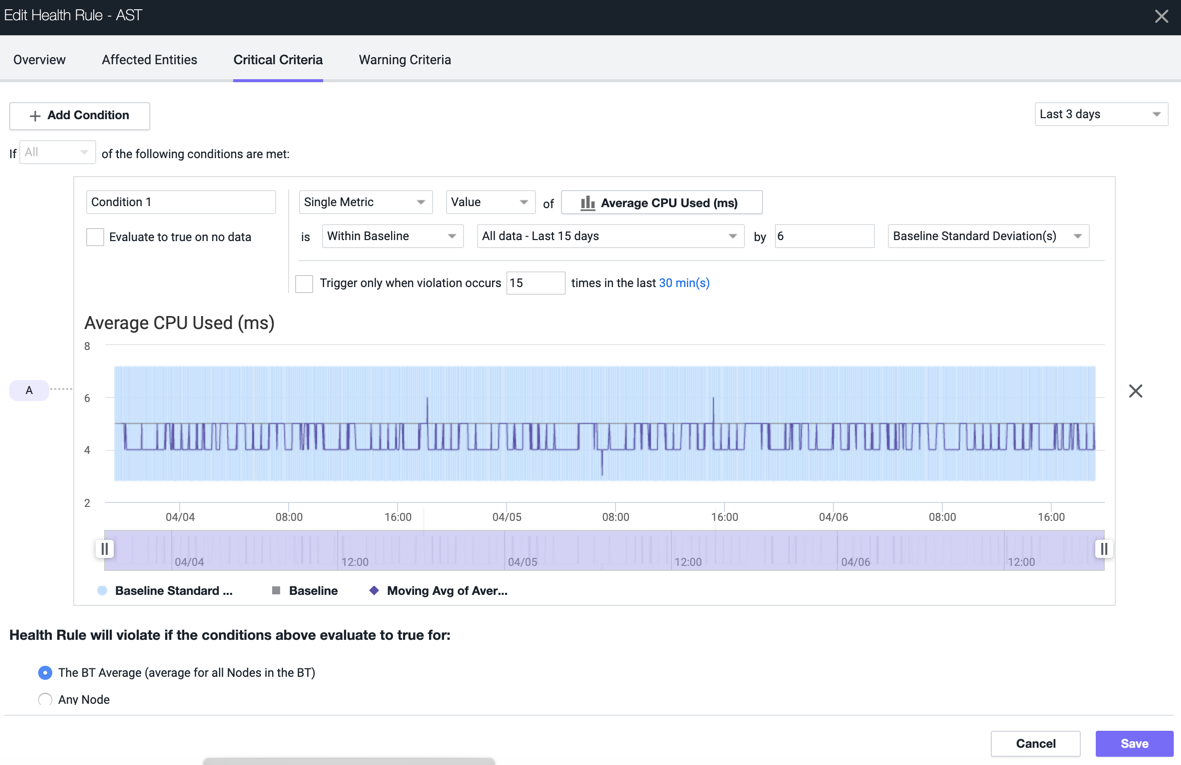
To avoid receiving false alerts and to ensure that you calibrate the sensitivity of health rules appropriately, you can use Alert Sensitivity Tuning (AST). AST helps you visualize the impact of the alerting configuration as and when you configure. AST provides instant insights in a graphical format that helps you fine-tune the alerts. Depending on the baseline configuration you define, a graphical view of the metric data for the given baseline configuration displays. The graphical view is instantly updated when you update any configuration. You can also view granular details by modifying the graphical view. The metric data presented in the graph helps you calibrate the sensitivity of the metric evaluation and the health rule.