アプリケーションの問題の根本原因は、インフラストラクチャの使用状況を測定するアプリケーション、ネットワーク、サーバ、およびマシンのメトリックを調べることによって特定できます。
たとえば、次のインフラストラクチャの問題により、アプリケーションの速度が低下する可能性があります。
- 一時オブジェクトのガベージコレクションに費やされた時間が多すぎる(アプリケーションメトリック)
- 2 つのノード間でパケット損失が発生し、その結果、再送信が発生し、コールが低速になる(ネットワークメトリック)
- プロセスが非効率であり、その結果、CPU 使用率が高くなる(サーバメトリック)
- 特定のディスクまたはパーティションに対する読み取り/書き込みのレートが非常に高い(ハードウェアメトリック)
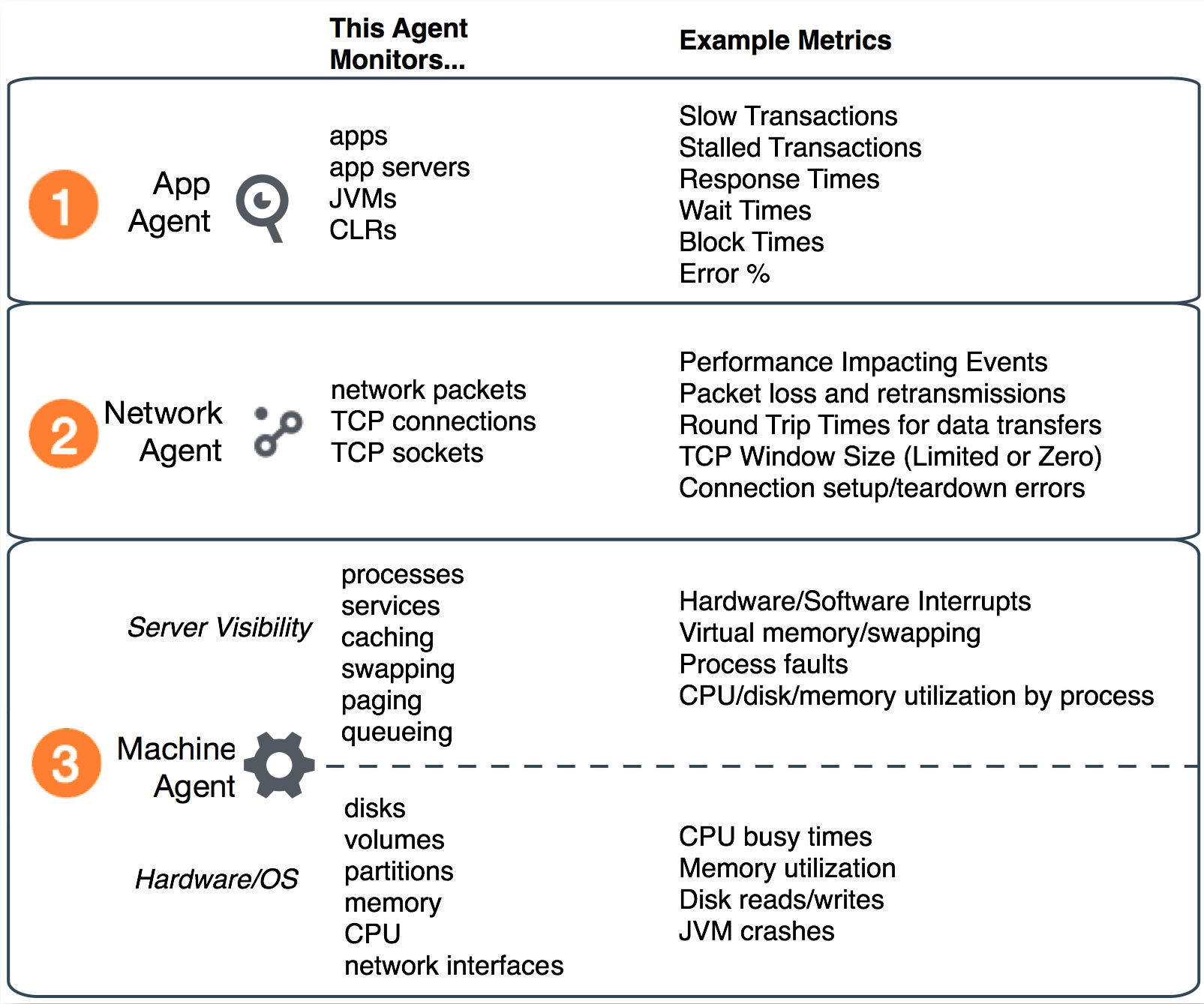
インフラストラクチャの可視性により、これらのタイプの問題を識別、特定し、トラブルシューティングできます。インフラストラクチャの可視性は、同じマシンでアプリケーション サーバ エージェントとともに実行されるマシンエージェントに基づきます。これらの 2 つのエージェントは、マルチレイヤモニタリングを提供します。
- アプリケーション サーバ エージェントは、アプリケーションに関するメトリックを収集し、低速トランザクション、停止トランザクションの問題、およびその他のアプリケーション パフォーマンスの問題があるアプリケーション、階層、およびノードを識別します。
- ネットワークエージェントは、各ノードで送受信されたネットワークパケットをモニタし、損失したパケットや再送信されたパケット、TCP のボトルネック、高いラウンドトリップ時間、およびその他のネットワークの問題を特定します。
- マシンエージェントは、次の 2 つのレベルでメトリックを収集します。
- ローカルプロセス、サービス、およびリソースの使用率に関するサーバの可視性のメトリック。
- ディスク、メモリ、CPU、およびネットワーク インターフェイスに関する基本マシンメトリック。
このマルチレイヤモニタリングにより、アプリケーションの問題と、サービス、プロセス、ハードウェア、ネットワーク、またはマシンのその他の問題との間で考えられる相関関係を特定することができます。
ネットワークの可視性
Network Visibility では、トラフィックフロー、ネットワークパケット、TCP 接続、および TCP ポートがモニタされます。ネットワークエージェントはアプリサーバーエージェントのAPMインテリジェンスを利用して、各アプリケーションが使用するTCP接続を識別します。ネットワークの可視性には以下が含まれます。
- ドロップ/再送信されたパケット、TCP ウィンドウサイズ(有限/ゼロ)、接続セットアップ/ティアダウンの問題、長いラウンドトリップ時間、パフォーマンスに影響するその他の問題に関する詳細なメトリック
- ティア、ノード、ネットワークリンクのKPI(重要パフォーマンス指標)をハイライトするネットワークダッシュボード
- ティア、ノード、ネットワークリンクのダッシュボードを右クリックして、トランザクションの異常値からネットワークの根本原因にクイックドリルダウンが可能
- TCP接続とアプリケーションフローの自動マッピング
- TCP接続を分割する中間ロードバランサの自動検出
- 個々の接続の高度な診断情報を収集するための診断モード
サーバーの可視性
サーバーの可視性 では、ローカルプロセス、サービス、およびリソース使用率がモニタされます。アプリケーション パフォーマンスの問題が、1 つ以上のノードのサーバパフォーマンスの問題に関連する場合、これらのメトリックを使用して時間枠を特定できます。
サーバの可視性は、マシンエージェントのアドオンモジュールです。サーバの可視性が有効な場合、マシンエージェントは次の機能を提供します。
- マシンの可用性、ディスク/CPU/仮想メモリ使用量、プロセスページフォールトなどの拡張ハードウェアメトリック
- Dockerコンテナ内で動作するアプリケーションノードをモニタリングし、アプリケーションのパフォーマンスに影響を及ぼすコンテナの問題を識別する
- Tier Metric Correlator によってティアの全ノードの負荷とパフォーマンスの異常を識別する
- サーバタグをインポートおよび定義する。サーバタグは、カスタムメタデータを使用して、関連するサーバの照会、フィルタ処理、および比較を行うために使用されます
- 内部または外部のHTTPおよびHTTPSサービスをモニタリングする
- サーバのグループ化のサポート。これにより、特定のサーバグループに正常性ルールを適用できます
- モニタ対象のサーバ ハードウェア メトリックに基づいて、特定の条件が満たされたか超過したときにトリガーするアラートの定義のサポート
基本マシンメトリック
マシンエージェントは、サーバの OS から基本ハードウェアメトリックを収集します。次の機能を提供します。
- サーバの OS からの基本ハードウェアメトリック(CPU とメモリの使用率、ネットワーク インターフェイスのスループット、ディスクとネットワークの I/O など)
- カスタムメトリックを生成する拡張機能を作成するためのサポート
- ランブックの手順を自動化する修復スクリプトを実行するためのサポート。オプションで、スクリプトが開始される前に人間による承認を義務付けるように修復アクションを構成できます。
- JVM クラッシュをモニタし、オプションで修復スクリプトを実行するための JVM クラッシュガード
Java と .NET インフラストラクチャのモニタリング
インフラストラクチャの可視性では、さまざまなエージェントを使用して Java 環境と .NET 環境がモニタされます。
- Java エージェントは、ビジネスアプリケーションと JVM のメトリックを収集します。マシンエージェントは、サーバの可視性とハードウェア/OS のメトリックを収集します。
- .NETエージェント は、ビジネスアプリケーションと測定対象 CLR のメトリックを収集します。.NET エージェントには、IIS とハードウェア/OS のメトリックを収集する .NET マシンエージェントが含まれます(「Windowsハードウェアリソースのモニタリング」を参照)。マシンエージェントは、サーバの可視性のメトリックを収集します。

インフラストラクチャの可視性の方法
次の方法を使用して、アプリケーションのパフォーマンスに影響するインフラストラクチャの問題を見つけることができます。
- 低速なトランザクションまたは停止したトランザクションに対してトランザクション スナップショット:スナップショットを使用して、特定のノードのインフラストラクチャ メトリックを関連付けることができます。これにより、低速なトランザクションまたは停止したトランザクションの根本原因を特定できます。
- メトリック相関:
- 1 つのワークフローの例として、マシンエージェントがインストールされたミッションクリティカルなサーバのノードダッシュボードを開き、次のタブでデータを相互に比較します。
- JVM(アプリケーションのパフォーマンス)
- JMX(サーバのパフォーマンス)
- Server(ハードウェアリソースの消費)
- ネットワーク ダッシュボード には、階層、ノード、およびネットワークリンクの右クリックダッシュボードが含まれます。これらのダッシュボードを使用して、アプリケーションの問題とネットワークの根本原因との間の相関関係を見つけます。
- Tier Metric Correlator により、コンテナまたはサーバで実行されているノードのクラスタで構成される階層で、負荷とパフォーマンスの異常を特定できます。
- 正常性ルール:ビジネストランザクションに影響が出る前に、ガベージコレクション時間、接続プールの競合、CPU 使用率などのメトリックに正常性ルールを設定して、サイクルで早期に問題を検出します。
- インフラストラクチャのルール、ポリシー、およびアラート:
- ビジネストランザクションに影響が出る前に、サイクルで早期に問題を検出するために、ガベージコレクション時間、接続プールの競合、CPU 使用率などのメトリックに対して正常性ルールを作成する。
- インフラストラクチャ メトリックにより重大レベルがレポートされたときにアクション(電子メールを送信する、診断を開始する、スレッドダンプを実行するなど)をトリガーするポリシーを定義する。
- JVM クラッシュガード と .NET マシンエージェント を使用して、それぞれ JVM クラッシュと CLR クラッシュのアラートを設定する。
- 重大なイベントに応じてスクリプトを実行するようにエージェントを設定する(たとえば、クラッシュに応じてアプリケーションまたは JVM を再起動する)。
適切なモニタリング方法を実施することで、ユーザトランザクションが影響を受ける前に問題についてアラートを出し、それらの問題を修正できます。